
inode是一个重要概念,是理解Unix/Linux文件系统和硬盘储存的基础。
我觉得,理解inode,不仅有助于提高系统操作水平,还有助于体会Unix设计哲学,即如何把底层的复杂性抽象成一个简单概念,从而大大简化用户接口。
下面就是我的inode学习笔记,尽量保持简单。
===================================
理解inode
作者:阮一峰

一、inode是什么?
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
二、inode的内容
inode包含文件的元信息,具体来说有以下内容:
* 文件的字节数
* 文件拥有者的User ID
* 文件的Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
* 链接数,即有多少文件名指向这个inode
* 文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
stat example.txt
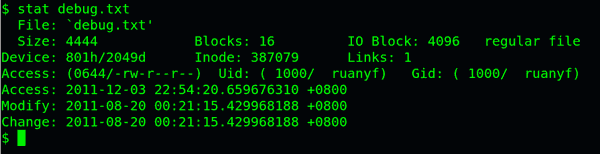
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
三、inode的大小
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
df -i
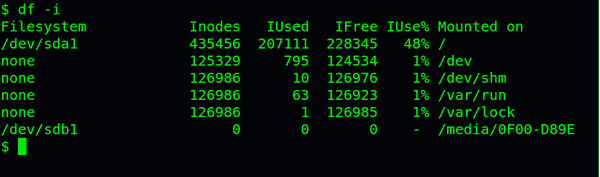
查看每个inode节点的大小,可以用如下命令:
sudo dumpe2fs -h /dev/hda | grep "Inode size"
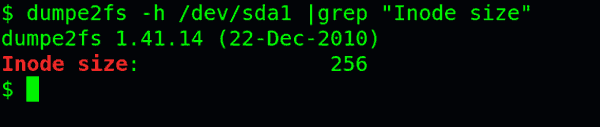
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
四、inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls -i命令,可以看到文件名对应的inode号码:
ls -i example.txt

五、目录文件
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls /etc

ls -i命令列出整个目录文件,即文件名和inode号码:
ls -i /etc

如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls -l命令列出文件的详细信息。
ls -l /etc
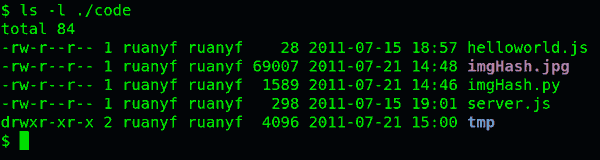
理解了上面这些知识,就能理解目录的权限。目录文件的读权限(r)和写权限(w),都是针对目录文件本身。由于目录文件内只有文件名和inode号码,所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
六、硬链接
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。
这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
ln命令可以创建硬链接:
ln 源文件 目标文件
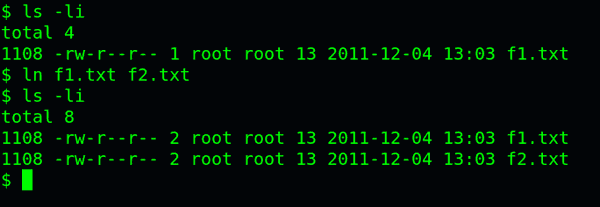
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。
反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录)。
七、软链接
除了硬链接以外,还有一种特殊情况。
文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录 目标文件或目录
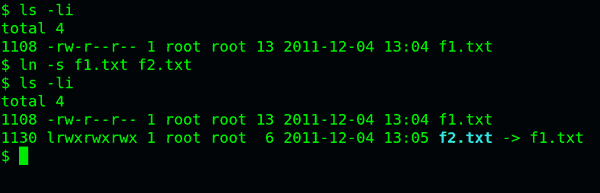
八、inode的特殊作用
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
1. 有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
2. 移动文件或重命名文件,只是改变文件名,不影响inode号码。
3. 打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
(完)

梁雄杰 说:
阮兄,您的rss在谷歌reader上总是报错啊,要过墙先可以转链接!fsck 命令修复文件系统或者修正受损的 inode ,就不用还原系统、或者甚至重新构建操作系统。唔知道阮兄有没用Fedora 16 ?
2011年12月 4日 13:41 | # | 引用
阮一峰 说:
如果 http://feeds.feedburner.com/ruanyifeng 不能用,就订阅 http://www.ruanyifeng.com/blog/atom.xml
2011年12月 4日 14:23 | # | 引用
freetstar 说:
通过inode来理解硬软链接方便多了,谢谢阮先生
2011年12月 4日 14:25 | # | 引用
zhy 说:
不会忘记软硬链接的区别了^_^
2011年12月 4日 15:12 | # | 引用
icyomik 说:
以前认为自己对INODE的认识已经够了,不过看了你的文章之后才知道自己知道的原来只是一小部分。
那个目录的硬链接数和平滑升级的原理之前是不知道的~
补充一下:`find . -inum INODE_NUM -delete`,用INODE直接删除文件。
2011年12月 4日 15:51 | # | 引用
Ken 说:
Windows Console的cd ..是怎么实现的?直接将..作为特殊参数处理?
2011年12月 4日 17:13 | # | 引用
nonoob 说:
教科书上的说法没看懂,阮先生的一篇博文让我从另外一个角度明白了inode是什么了,谢谢!
2011年12月 4日 18:04 | # | 引用
酷呗 说:
好文章。特殊作用的第3点的意思是,新版文件的更新是更新在新的block上,然后下一次运行的时候旧inode被回收同时旧文件被删除么?那下一次运行的话是通过什么来让文件名指向新的inode呢?
2011年12月 4日 18:35 | # | 引用
Todd 说:
“每一个文件对应一个inode,硬盘上有多少文件,就有多少个inode”和“inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode”是否矛盾??
2011年12月 4日 19:20 | # | 引用
依云 说:
“文件名包含特殊字符,无法正常删除”——这个还没遇到过。
提到这个我就郁闷。我一直认为 cd.. 是一种特殊的用法(.. 前没有空格;当时的老师/电脑杂志从来没有说那里可以有空格),刚接触 Linux 时在 shell 输入 cd..,结果报错,搞得我不知道怎么进入上一级目录了。。。
2011年12月 4日 19:44 | # | 引用
Zind 说:
“硬盘上有多少文件,就有多少个inode”,这句话,说法上好像是有些问题。当然,阮兄的意思大家都明白的。
另外,根据阮兄的截图上的字体和配色来看,用的发行版似乎是 Fedora?
2011年12月 4日 20:29 | # | 引用
阮一峰 说:
@Todd:
谢谢指出。
我确实写错,已经改过来了。
2011年12月 4日 21:01 | # | 引用
ys0290 说:
inode是文件的花名册?
2011年12月 4日 22:21 | # | 引用
dongZ 说:
windows好像是从vista开始也有硬链接软链接,同步目录的时候很有用,以前一直没搞明白软硬的区别,现在总算明白了
2011年12月 4日 22:25 | # | 引用
nswutong 说:
win上面的mklink和linux不能比,各种BUG
2011年12月 5日 03:46 | # | 引用
Goblin 说:
程序都是先读入内存再执行的,所以并没有“运行中的文件”,程序运行时不需要读写程序文件
2011年12月 5日 04:29 | # | 引用
ufox 说:
作者应该写明很多技术细节是针对Linux的Ext2系列文件系统,也就是从属于传统的Unix文件系统衍生系列。而目前风头正旺的Solaris ZFS或者Linux Btrfs在实现上有很大的区别,比如动态inode分配等。
2011年12月 5日 09:09 | # | 引用
ncsglz 说:
在鸟哥的私房菜上看过的,不过这里了解了无重启升级,哈哈
2011年12月 5日 10:20 | # | 引用
mn 说:
linux学习的不多,但来到楼主这,相信一定能学到不少东西的。
2011年12月 5日 10:28 | # | 引用
HoNooD 说:
非常简明易懂。感谢~
2011年12月 5日 14:13 | # | 引用
rabbit 说:
每1k或2k设置一个inode,而block的大小为4k,一个文件至少占用一个block(4k),可用的inode应该远多余文件的数量,应该不会出现文中描述的“inode已经用光,但是硬盘还未存满的情况”,不知道我的理解是否有偏差?
2011年12月 5日 22:32 | # | 引用
Ansen 说:
学习了,我转载了 并附上了原文链接
2011年12月 6日 08:52 | # | 引用
后生力量 说:
有阮老师教学就好多了,比垃圾的教科书强的多的多
2011年12月 7日 10:09 | # | 引用
NGloom 说:
学习了,非常受用。
2011年12月 7日 23:37 | # | 引用
Randy 说:
有点没明白:一般规定每1k大小就有一个inode来作为其元数据;一个文件也得有一个inode。
那一个文件超过1k,比如50k大小,那么它用几个inode来进行表示呢?
另外,关于block,我之前看过的一些资料上说:一般2个sector构成一个block,而4个block构成一个page(一般为4k),在FS中进行页高速缓存时用的就是这个Page单位,使用FS进行访问IO时,首先通过这个Page cache,然后到达block层,继而调用IO的driver层,进行硬件的sector单位的操作。。
2011年12月 9日 23:09 | # | 引用
邓泽西 说:
我想到在ios设备上删除一个程序,点一下X,能马上删除,而不是像windows那样等待很久才删除。
这是不是通过删除inode来删除文件呢?
2011年12月10日 20:07 | # | 引用
micy 说:
补充一个常见的关于inode的坑:
当一个inode被一个程序打开,并且有写入时。
如果另一个进程删除这个文件,可能造成目录下找不到这个inode,但该inode对应的空间并未释放的情况。
2011年12月12日 20:09 | # | 引用
Liu Liu 说:
对!inode是一个抽象(interface),并不是一个实现(implementation)
2011年12月14日 06:45 | # | 引用
vanxining 说:
我刚好模拟实现了一个简单的UNIX i-note风格的文件系统。
假如早点看到这篇文章就不用我辛苦查阅资料了。
有些地方忍不住说一下:
1、一个i-node只对应一个实际文件,一个文件也会只有一个i-node。最原始的i-node表大小是固定的,因此一个磁盘可以存放的文件数目是固定的。i-node主要用在目录中标识目录下的文件。
2、“.”和“..”是目录中的两个目录项,但cd ..究竟是由shell还是由文件系统来处理这个不大清楚,应该是文件系统吧,虽然后者也可以做。可以写一个程序验证一下
test .
打印出来看看是得到“.”还是真实路径。
2011年12月14日 23:37 | # | 引用
vanxining 说:
对于i-node的实现,《现代操作系统》有很详细的说明。
2011年12月14日 23:38 | # | 引用
風雨斷腸人 说:
學習了。
我的理解:
linux/unix通過inode號碼來定位文件,就好比在普通的MIS系統裏通過每個實體的ID來操作實體信息(對應數據庫中的記錄)一樣,文件名只是用戶層使用的標識,好比每個實體(記錄)有一個字段顯示該實體的描述信息
2011年12月20日 14:41 | # | 引用
yangbinxom 说:
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
这里旧的文件为什么就会被回收掉,系统中什么样的机制是实现这个的呢?通过时间信息来吗?
2011年12月26日 16:12 | # | 引用
kingsuey 说:
我的理解是,旧版文件的inode里的“链接数”已经为0了,所以系统会自动回收对应的inode及其对应的block区域。但是我不解的是,假设在更新之前,有N个文件名对应着这个inode,在更新的时候会把那N个链接数都清零吗?另外,下一次软件运行的时候,为什么文件名就会自动指向新版文件呢?似乎我的思维已经固化在windows下了。
2012年1月16日 17:42 | # | 引用
littlekfc 说:
我的理解是更新的时候会更改文件名对应的inode,使它自动指向新版文件,下一次运行通过文件名打开,自然指向新的了。我对您说的第一个不解也表示困惑。此外,一个软件的运行会打开别的文件,软件运行时打开别的文件是通过文件名的,但万一那个文件更新了,指向新的文件很有可能会崩溃的。软件更新貌似不像您貌似得那么简单啊。
2012年2月14日 23:28 | # | 引用
Lovocas 说:
读完有点不理解的地方?
“inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。”
为什么是每1kb设置一个inode呢?
inode中记录文件数据block的位置, 那么说明文件最小就是一个block的大小了?
规划inode的个数就可以先算硬盘最多有多少个block(文件)
所以 inode个数 应该是小于 硬盘大小/block大小?
2012年2月17日 19:36 | # | 引用
Pitt Mak 说:
我在想一个问题,阮大哥为什么能涉猎广泛,想来想去,突然我想到很久前自己刚接触电脑那会,关于电脑的一切,我都有兴趣,后来慢慢的接触多了,就只局限于对某个领域的学习了。
是不是可以这样认为,阮大哥对电脑的好奇心一直保持在一种非常高的状态,所以,才能对那么多个领域都有所涉猎呢。
而要保持这种好奇心,对于我来说,只能是看到那种领域的知识是不是对于自己是不是有用。
自从看完《我是传奇》这部电影以后,我就有了一种意识,很多时候,当周围或者说一定范围内,只有靠你自己的能力来生存的时候,自己平时的知识就将决定你的命运。所以,从现在起,我要培养自己对知识的积累,相信有一天这些知识在自己面临困境(假设一下:当在一个完全没有网络的环境里,我需要设计一套xx系统,而我所知道的关于这方面的知识的价值远比网络上目前能查到的知识大)的时候,能派上用场。
2012年5月24日 21:49 | # | 引用
Pitt Mak 说:
不是说不删除留言吗?
怎么把我的留言删除了?
失望!
2012年5月25日 21:10 | # | 引用
Sangwf 说:
写得很好,非常清晰,排版也很好。
2012年8月15日 08:46 | # | 引用
Yanfei YIN 说:
读完这篇文章,我才找到了前不久服务器硬盘空间未满但是无法创建文件的原因,感谢作者!
2012年8月19日 14:41 | # | 引用
Candochen 说:
请教下linux进程读取一个文件,会把这inode信息对到进程的内存空间去吗?
2012年9月13日 19:11 | # | 引用
tsuibin 说:
如何获取一个文件的struct inode结构体?
2012年10月22日 10:21 | # | 引用
Liszt 说:
“所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录)。”
根目录是个例外。
2013年4月25日 10:29 | # | 引用
coder_L 说:
2013年4月29日 19:07 | # | 引用
hall 说:
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
其实这句话就是所谓的内部碎片是吗??
2013年5月31日 14:54 | # | 引用
Joseph Pan 说:
不错,读完之后对 inode 有了更深入的了解,也明白了硬链接、软链接、平滑升级的原理。
2013年10月 7日 12:04 | # | 引用
Hector Huang 说:
阮兄的文章里已经写了,旧版的软件运行只需要inode,不需要文件名,文件名在更新的时候直接指向新的软件,这样旧版的软件在停止运行的时候所占用的block和inode直接被回收。
2013年10月30日 17:15 | # | 引用
鲜活 说:
读完之后对 inode 有了更深入的了解
2014年1月 8日 09:03 | # | 引用
呵呵 说:
前一句话刚说出,后面一句就把前面那句否定了
如果. 和 ..都是指向自己,是不是应该是3+子目录数
2014年4月25日 15:07 | # | 引用
aa 说:
inode数量在硬盘格式化时就已经定了,所以会造成inode用光的情况。
2014年5月29日 22:57 | # | 引用
sky 说:
阮老师,硬链接创建后通过ls -li显示目标文件和硬链接的大小都是一样的,而软链接的大小比目标文件小很多,可是为什么说创建硬链接不会消耗空间,而软链接是创建了文件消耗空间,谢谢!
2014年10月12日 20:07 | # | 引用
sadhen 说:
2014年11月 4日 21:36 | # | 引用
linchen 说:
好文。 终于理解了硬链接和软连接!
2015年1月 7日 15:02 | # | 引用
chaoqunlu 说:
虽然作者写得不错,但缺少整个知识点连贯性和系统性,《鸟哥的私房菜》里面对整个文件系统都讲得比较透彻,没有那种空中楼阁得感觉。建议大家看看。
2015年3月24日 00:36 | # | 引用
卢伟 说:
阮大哥,有没有方法通过发送命令的方式来获取Linux文件系统的所有inode列表呢?目的是扫描扇区,获取已经占用的block呢?
2015年4月27日 17:37 | # | 引用
Gypsy 说:
请问楼主,inode号码是从多少开始的?
2015年5月 4日 10:58 | # | 引用
jay 说:
请问有没有比较好的方法可以检查u盘里面(或硬盘里面)的数据有没有变动, 也包含只是移动文件夹
2015年8月15日 10:59 | # | 引用
Rayman 说:
请问,查看linux中文件的inode信息 ,这个可以用什么已有的Linux命令来实现吗?
2016年8月25日 10:59 | # | 引用
STONE-CHN 说:
请问,文章里说操作系统通过inode中来定位文件在磁盘中的block位置,可是操作系统通过什么方式快速找到“文件对应的inode”的存储位置呢?
2016年9月19日 18:51 | # | 引用
kakaaaluote 说:
写得真清楚,非常感谢。
2016年12月 8日 15:15 | # | 引用
pxf_god 说:
所以如果只有读权限,只能获取文件名,无法获取其他信息,因为其他信息都储存在inode节点中,而读取inode节点内的信息需要目录文件的执行权限(x)。
纠正一下
1. 不只能获取文件名,还包括inode号。
2. 要读取inode节点内的信息,需要该inode的r权限,不是包含该inode的目录inode的x 权限, 目录的x权限只是决定chdir系统调用(cd到该目录)能不能成功
2016年12月29日 09:54 | # | 引用
maxie 说:
学习了,讲的很棒(已收藏)
2017年3月27日 16:04 | # | 引用
wang 说:
我想问的是,文件名不在inode里面存,也不在文件里面存,那究竟存在那里呢?
2017年7月22日 10:10 | # | 引用
Devshoo 说:
我也好奇, 查了一下, 这篇文章有提到, 说是存在目录项中.
2017年7月23日 02:12 | # | 引用
Crow 说:
阮老师,对于硬链接中的这句话"对文件内容进行修改,会影响到所有文件名",我不是很明白具体是怎么修改,比如有文件A和B,B是文件的A的硬链接,如果修改B的内容也会影响到文件A的内容吗?
2017年10月 3日 23:27 | # | 引用
Pipapa 说:
会影响的,都是更改同一个inode下的文件,A/B都是修改相同的block
2017年10月16日 13:40 | # | 引用
赵 说:
你好阮老师,有一个疑问,我从书上硬盘的磁道上的扇区最小是512byte,那么系统格式化硬盘时时如何将inode分割成126byte或256byte的
2018年1月13日 22:20 | # | 引用
Frank_wang 说:
linux 下查看 文件 大小是4k, stat查看inode信息,Blocks 是8.
那是这个文件是占用8个块。 而系统中每个块大小是4k.
这么算文件应该占用空间大小应该是 32k才对啊。
那为什么实际占用的是4k大小呢?
那么linux 系统下stat 文件出来的 Blocks 又是什么含义呢?
谢谢您。
2018年8月24日 15:06 | # | 引用
screamsyk 说:
对于不同的文件,它们对应的 inode 中存储的文件数据所在“块”(block)的位置有没有可能一样呢?
如果有可能一样,那么这属于“软连接”吗?或者又是一种特殊情况
2019年2月20日 20:39 | # | 引用
hitjackma 说:
假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。这里应该是 12.5%吧, 128/1024=0.125
2019年4月11日 14:03 | # | 引用
Jasonwu 说:
大大,请教一下文件名和它的 inode 编号放到目录的 data block 里面,目录的读权限刚好控制 data block 的读取。为什么通过其它方式知道目录里的一个文件的文件名之后,就不需要读取目录的 data block了,如果是这样,它是从哪里得到这个文件的 inode 编号的?
2019年4月17日 10:01 | # | 引用
Alex 说:
"表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步: 首先,系统找到这个文件名对应的inode号码; 其次,通过inode号码,获取inode信息; 最后,根据inode信息,找到文件数据所在的block,读出数据。"
"读取inode节点内的信息需要目录文件的执行权限(x)"
这里我混乱了,读文件不也需要获取inode信息吗..为啥不用执行权限?2019年7月 4日 09:04 | # | 引用
关中刀客在青岛 说:
看前端性能优化,找到浏览器缓存,再找到协商缓存,再找到Etag生成原理,再找到iNode就到这里来了……
2019年8月20日 12:29 | # | 引用
阿川 说:
阮老师 牛皮,十分清晰
2019年8月22日 16:08 | # | 引用
YourLi 说:
试了下
目录文件只给 读权限,是获取不到 inode, 也就是只有 读权限的目录 ls -i 的返回结果为 ? 文件名
这个? 就是 inode.
所以 读权限只能获取 目录文件 列表项的文件名, 而 执行权限 才可以获取到 目录文件 列表项的 inode 号. 有了 inode 号才可以获取信息
2021年2月22日 12:55 | # | 引用
Jerry 说:
已知 Links >= 2 的情况下,是否有办法可以查到所有 Links 到路径?
2021年4月26日 14:22 | # | 引用
噼里啪啦 说:
您好 想知道,啊a,b分属两个文件系统,ln -s b a,现在b文件夹所属的文件系统inode已经满了,我现在还能在a中创建文件吗?如果能是不是说现在b中的文件所使用的inode是a那个文件系统的。
2021年5月21日 10:55 | # | 引用
Winux 说:
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
这里不太懂,如果一个大1M的文件是对应一个inode还是1024个inode?有点晕了!
2021年7月27日 11:47 | # | 引用
zhu 说:
”第3点使得软件更新变得简单。。。“ 对这点,不太理解,当更新时,新版文件以同样的文件名,生成一个新的inode,那么,老的inode不就是没有文件指向了吗,不就会被删除吗
2021年9月 7日 15:26 | # | 引用
WCD 说:
文中不是有吗? ls -i
2021年11月11日 23:37 | # | 引用
Jaya 说:
感谢阮老师的对于inode的讲解。使我对操作系统文件管理这一块理解提升了一个层次。☆⌒(*^-゜)v THX!!
2021年12月 5日 08:53 | # | 引用
LaoYueHanNi 说:
`打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。` 运行时不考虑文件名,所以不会删除啊,停止运行后应当就会删除了
2021年12月30日 14:36 | # | 引用
像我这样迷茫的人 说:
“inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。”
1. 这个说法是不是有问题啊?inode节点和inode区是不是指的同一个东西?
2. “假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。”为什么会达到128MB啊?1KB * 128字节(btye) = 1024(KB) * 128(KB) = 131072(KB).远远不到128MB啊,是我哪里理解的有问题吗?
2022年4月28日 17:53 | # | 引用
tengfei 说:
感谢您正本清源, 简洁精炼的表达,看一遍就念头通达了。
2022年5月21日 20:13 | # | 引用
Frankie 说:
通常购买硬盘时,产品参数所指的 1GB 容量其实只有 1000MB 大小,而不是 1024MB。但平常单位换算用的是 1024,所以...
2022年7月 9日 22:57 | # | 引用
undefined 说:
阮老师,你说"除了文件名以外的所有文件信息,都存在inode之中",第一行的File: 'debug.txt'不是文件名吗?
2022年8月18日 15:26 | # | 引用
Zach 说:
注意第八节第 3 点,`通常来说,系统无法从inode号码得知文件名。`,因为有可能有多个硬连接指向同一个 inode,无法单纯从 inode 反向查找多个硬连接文件名。至于第一行的 File 信息,感觉应该是执行 stat 命令时候已知传入的就是 debug.txt 这个文件名,所以直接在输出里面附加上了这个信息。
2023年3月16日 18:48 | # | 引用
xiang 说:
那系统读取对应inode的时候,是读一个inode还是inode所在的块都读进去呢,应该是按块吧
2023年12月15日 17:53 | # | 引用
nicefox 说:
深入透彻!十三年前的文章还能这么有帮助,感谢博主的分享。
2024年4月 1日 23:26 | # | 引用