
今天,我在网上看到一张图,据说是来自Google内部的统计----世界上所有网页编码统计图。
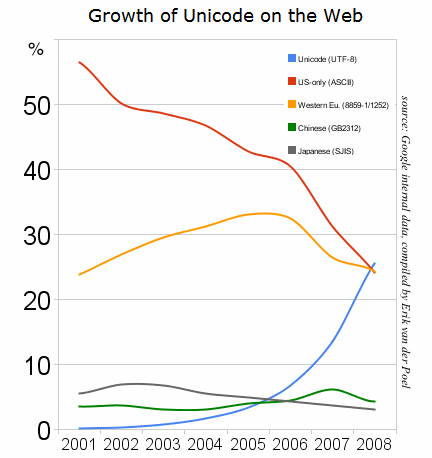
第一眼看到这张图,我感到很振奋,utf-8编码终于成为了主流。
可是再看第二眼,顿时就泄气了。因为份额下降的是ASCII和ISO 8859-1这两类编码,而GB类的中文编码份额几乎保持不变。那样的话,utf-8编码份额的上升,其实没有多大实际意义,因为ASCII和ISO 8859-1本身就是同utf-8兼容的,转不转化无所谓。
GB类的中文编码,才是真正需要被淘汰的。除了最基本的ASCII码,它同所有其他编码都不兼容,为互联网应用带来无尽的麻烦。许多很简单的问题,就是因为要考虑语言转化,而变得无比麻烦。
可是,直到今天,我们国家主流的门户网站,全部都是GB2312编码,这让人无法理解。我怀疑是不是有什么法规,规定一定要这样做。如果真是这样,那么实在是太愚蠢了。
P.S.
想了解字符编码基本知识的朋友,可以参考我以前的笔记。
(完)

22 说:
中文utf8也麻烦,还有unicode-8,unicode-16,unicode-32,ibm14401(不记得数字了,随便写个)什么的大字符集
即便是中文gb2312,实际上windows上的gb2312就是gbk
2008年5月 6日 23:32 | # | 引用
LI Daobing 说:
iso8859-1 与 UTF-8 不兼容
2008年5月 7日 08:38 | # | 引用
atlas 说:
那台湾的Big5和香港的编码与UTF兼容吗?
2008年5月 7日 09:35 | # | 引用
aa 说:
2008年5月 7日 10:38 | # | 引用
Ruan YiFeng 说:
big5也属于应该被淘汰的编码。
我写得不准确,应该是iso 8859-1与Unicode兼容。
2008年5月 7日 11:36 | # | 引用
Fwolf 说:
隐约记得gb2312作为国标编码,是有规定要求在某些地方必需要使用的
(希望下一位来补充)
2008年5月 7日 14:23 | # | 引用
donews 说:
阮先生能不能够处理一下多维新闻的全文RSS乱码问题。
我在第一时间就订阅了阮先生制作的多维和德国之声两个全文RSS。但现在发现多维RSS的乱码很严重,不知道有没有办法解决。
2008年5月 7日 15:16 | # | 引用
... 说:
我猜。。。gb2312普及是因为dreamweaver默认设置的字符集就是这个。。。。
2008年5月 7日 16:44 | # | 引用
Ruan YiFeng 说:
2008年5月 7日 23:16 | # | 引用
Ruan YiFeng 说:
2008年5月 7日 23:18 | # | 引用
阮一峰网友 说:
赶快淘汰国标编码,那是上一代的落后者用的垃圾。反正我国门户网站也没什么好东西。
2008年5月 8日 17:29 | # | 引用
伊水笑 说:
UTF-8的编码还是不错滴……
应该成为主流啊。
2008年5月 8日 21:53 | # | 引用
clino 说:
gb 码至少有个好处,传输和存储所占的空间比 UTF8 会少一些
2008年5月 9日 15:01 | # | 引用
ppip 说:
这个还是需要时间的,更需要的是国际化的视野。
如果只针对国内用户,GB又如何呢?
2008年5月13日 21:42 | # | 引用
Ruan YiFeng 说:
不是只考虑网页浏览的,还有feed的编码。很多时候会用feed的聚合,编码不一致就很麻烦。
2008年5月14日 20:37 | # | 引用
xun 说:
对于中文字符远远超过英文字母的内容,UTF8岂非比原始的Unicode更浪费存储空间
2008年5月21日 16:43 | # | 引用
徐保才 说:
我想用uft-8编比较好,原因之一是学习PHP语言中有许多程序是要求用这个编的,用GB会出现小方框,可是我找了许多输入法,只有南级星是支持UFT-8的,输入里面可以,但只显示一半字,无耐。
2008年6月 3日 17:36 | # | 引用
杨曦 说:
前几天我刚刚被文字乱码搞的郁闷。。。项目最好用utf-8统一最好,放到哪里都不会出现乱码,页面文件都要utf-8,js,css包括java语句里面只要有response的都要设置成utf-8输出
2008年6月14日 11:00 | # | 引用
杨曦 说:
博主,你的这个按钮很搞笑哦。。。“
还有你检测一下,如果是同一个session 就不用让人家重复的输入大名,电子邮件,直接记住就好了,当session关闭的时候你清空一下
2008年6月14日 11:03 | # | 引用
flyinflash 说:
1、如果是流量大的网站,使用非UTF8主要是因为流量,流量是要算钱的,UTF8一个字1符是其它的两到三倍,像中文这类亚洲字符,自然大多数情况是三倍以上
如果一个网站一年的网费是500万,使用UTF8就是1500万……
2、其它流量不咋样的网站
主要就是TMD的WINDOWS。国内一群猪都是使用TMD的WINDOWS作教育工具,应试也是TMD的WINDOWS,WINDOWS没有以UTF8为核心的概念,所以那些无辜的学生认识UTF8的重要性概率大大降低。
使用LINUX的学生就不会,LINUX下几乎什么都是UTF8的,一来国际化省事,本地化也省事。
2008年7月14日 21:35 | # | 引用
flyinflash 说:
请把上面的“TMD”去掉
2008年7月16日 01:54 | # | 引用
spider 说:
不用把 TMD 去掉,那些蠢猪该骂
2008年7月31日 11:57 | # | 引用
redspider 说:
2008年8月 1日 09:39 | # | 引用
您的大名 说:
utf8是对中文等象形文字的歧视
英文只用一个字节,
法文等一些用两个字节
中文最少三个字节。
用gb2312可以大量降低存储和宽带开销
2008年8月24日 07:46 | # | 引用
koaqiu 说:
但是我知道中文必须要两个字节才能表示完整的
2008年8月25日 13:51 | # | 引用
kopision 说:
2008年8月27日 18:50 | # | 引用
林海枫 说:
UTF-8只是Unicode编码方式中的一种,与UTF-16相比,它的最小编码单位是字节,而UTF-16编码的最小单位是双两节。UTF-8最大的好处是可以与ASCII兼容,因此,英文字母在ascii和utf-8中的数值是一样的,用一个字节的储存空间就可以了,UTF-8事实上就是这样的。千万别和我说需要两个字节。而在中文根据UTF-8的编码规则,要用三个字节来储存,千万别和我说需要两个字节。
而UTF-16是以双字节为编码单位的,因为无论英文和中文,至少需要2个字节的储存单位,而事实上,他们都是两个字节来存放(这并不代码所有的unicode字符仅需要两个字节就可以了,有一些是需要4个或更大)。
对于Unicode编码方式来说,如果内容为英文,采用 UTF-8编码方式最省空间,每个字符只需要一个字节就可以了。如果内容为中文,采用UTF-16编码方式最省空间,每个中文文字需要两个字节(相反在UTF-8中需要三个字节)。
UTF-8和UTF-16都是Unicode的编码方式,可以相互转换。gb2312也是国际编码,应该可以与Unicode完全兼容,换言之可以转换。
故对于中文网页来说,应该使用UTF-16, 这样空间占用最少,而且支持Unicode的浏览器都可以正确转换;我想gb2312也一样(但未证实)
因为对于中文网页,应使用UTF-16或gb2312,而不应该使用UTF-8
其实Unicode的编码方式有好几种,除了上面两种外。之所以有好几种,是根据不同语言文字的需要而提出的。
2008年12月10日 10:23 | # | 引用
华晨 说:
我也在学习网站制作,也被utf-8编码困扰着
2008年12月16日 14:19 | # | 引用
我的大名 说:
utf-8汉字多一字节也没什么吧?本来汉字就多,事实上,gb18030里双字节还不够用了,甚至有用更多字节的。而utf-16有字节序问题,utf-8则没有。
另外楼上有位朋友还扯到什么歧视上去了。这有点好笑了。人家英文有几个字母呀?难道你想所有汉字用一个字节来表示?
2008年12月24日 02:00 | # | 引用
您的大名 说:
博主很搞笑,GB是“国标”的意思,国家不用国标用什么?有什么难以理解的?
2009年4月29日 16:03 | # | 引用
按了两下 说:
希望全世界统一编码啊
2009年5月 2日 13:58 | # | 引用
mark 说:
GB18030兼容GB2312,常用字都是双字节,只有生僻字采用4字节。而UTF-8汉字全部都是3字节。并且unicode在BMP上对汉字的确有“歧视”,不遵循汉字的习惯而是以老外的方式来组织。
2009年5月25日 15:09 | # | 引用
mark 说:
2009年5月25日 15:15 | # | 引用
mark 说:
有关GB18030编码来由的传说
简单说一下我对这段历史的理解吧,说错了欢迎大家指正。
1,GB2312是很老的东西了,早就发现不够用了。
2,94年(还是之前)国家推出了建议性标准gb13000,这个标准其实就是utf-8标准(除了名字,完全一样),同时也建议微软公司采纳。--(据说是1993年,GB13000,应该是ISO10646)
3,微软借口说gb18000还不成熟,为了取得中国市场的垄断地位,自己搞了一套汉字标准,于是它就随着win95和office之类的流行起来了,国家看生米已经煮成了熟饭,只好把这套标准定为国标GBK标准。--(其实只是指导性标准,并非强制性,GB18030是强制性标准)
4,微软到了99年(前后吧),又说GBK已经落伍了,现在流行utf-8标准,准备全盘转换成utf-8,这些把有关部门惹怒了。NND,当年我们推utf-8你说不成熟,自己搞了一套,现在赚得盆满钵满了又自己说要推utf-8了,你丫微软分明就没把政府放在眼里。
5,于是政府怒了,强制推行gb18030标准(这个标准前面兼容GBK,其他码位兼容utf-8),算是过渡标准吧。要求微软强制执行,否则产品不得在大陆买。于是基本搞死了微软的WindowsMe,差点搞死了Office2000(据说发行前几个月,微软除了改字符编码就没干其他什么事情)--(确实,WinMe是我认为的最差的Windows版本,而office2k也是前不着村,后不着店,前后兼容性都差)
6,由于以上历史原因,现在就是GB2312,GBK,GB18030,UTF-8并存了。
7,如果不是万恶的微软,我们早就用上UTF-8了。
8,所以说微软和政府关系一直很僵,不是说着玩的,微软太目中无政府了。
9,以上是我从其他地方看来的,可能记得不是太真切了,说的不对请大家指正。
【按】这是在水母Linux版上的讨论所引发的。只有用Linux的普通用户才会关心编码问题,因为选择太多了,选哪个好确实是个问题。从长远看,应该选 utf-8,可从一般使用角度来看,GBK足够也适合以前的文件现状,并且也可以同UTF-8编码的人交流,程序支持就是了。所以我目前还是用GBK。也许应该用Utf-8。香港政府倒是在推广ISO10646的,还有免费字体供应。
http://tech.it168.com/knowledgebase/Articles%5C1%5C5%5C5%5C155d3300879cd9a41b90c4d7ff8c1c1b.htm
2009年5月25日 16:13 | # | 引用
草窟人生 说:
呵呵,MS我一开始就都用的 UTF-8,没有用过其他编码,好像使用 GB2312, 对 GOOGLE.COM 收录不好
2009年8月28日 11:54 | # | 引用
Axpwx 说:
用gbk主要考虑的是存储成本,没有别的因素。
2009年9月17日 02:05 | # | 引用
lowsfer 说:
那么GB2312和UTF-16编码是不是就歧视英文了?人家英文本来好好的ASCII一个字节就可以了,把其他语言的整进来,拖累得英文要两个字节了。人家是不是应该抵制所有非ASCII,非UTF-8的编码??
不要什么事情都往狭隘的民族主义上面扣!
2010年11月14日 17:24 | # | 引用
哈哈哈 说:
博主你的图片的来源是Google的官方博客http://googleblog.blogspot.com/2008/05/moving-to-unicode-51.html
现在有了新的数据 http://googleblog.blogspot.com/2010/01/unicode-nearing-50-of-web.html
请查看。
2011年6月26日 21:46 | # | 引用
mark 说:
你没看懂我的意思。我是说unicode在BMP基本页面上面对汉字有点歧视,编排(大部分?)汉字不在BMP内导致汉字基本都是3字节编码。否则可以做到一二级字库在UTF-8下都是2字节的。当然这个和有关部门不作为应该有关系……
还有你没分清楚UNIOCODE和UTF-8/UTF-16的关系,前者是字符集,后者是编码(传输)方式。在UTF-8编码下拉丁字母都是一个字节的(德文的那5个特殊字符好像也在127下,不过需要修改系统默认字符集为德文才能正常显示)。
2011年9月25日 20:54 | # | 引用
mark 说:
ps: 在GB2312编码下拉丁字母也同样的一个字节。
2011年9月25日 20:55 | # | 引用
看问题片面 说:
博主又要不懂了,像新浪那样的大型新闻网站,用UTF8你算算每天要增加多少流量,服务器负荷增加多少?外国为啥推UTF8,他们定的MD当然首先考虑西欧字符哪把亚洲地区文字考虑进去。MD要适合国情我们来定个通通双字节的国际编码你看他们还有这么积极?不是同一个道理,不然你当新浪搜狐都是傻子,UTF8好、合算还不用?我看傻的是你人云亦云看问题太片面了。
2013年2月20日 21:30 | # | 引用
睽睽 说:
linux下默认使用UTF8对文件名进行排序,担着造成了使用不便的问题。
原因是其对中国人所习以为常的汉字检索顺序(如: 注音顺序、拼音顺序和笔画顺序等)均不能提供支持,以致linux系统的NAS文件通过网络共享到其他设备上时不便于人们直观查看。
举个实例,网络上有一台NAS,其上共享了许多课件。以前使用的是Windows的系统搭建,后来改用Linux系统。其上所共享的课件名称一般形式为“日本语文xx.avi”、“中国语文xx.avi”、“美国语文xx.avi”……,数量众多,使用上也不好再对其进行分类建立目录,只能按照文件名的拼音顺序进行检索。
这在以前的Windows系统的NAS上没问题,因为windows默认按照GBK进行文件名排序的,采用的就是非常符合大多数中国人习惯的汉语拼音排序法,其网络磁盘显示的文件名顺序为:
德国语文01.avi
德国语文02.avi
美国语文.avi
……
日本语文01.avi
日本语文02.avi
日本语文03.avi
……
中国语文01.avi
中国语文02.avi
……
这完全符合A~Z的大陆汉语拼音排序法。所以上课时,教师在网络播放机查看网盘文件时非常直观方便,节省不少点选时间。
但采用了Linux系统的NAS后,其默认按照UTF8的方式输出文件名排序,通过网络共享后,网络播放机上看到的网络磁盘文件顺序就乱套了:
日本语文03.avi
日本语文01.avi
日本语文02.avi
……
德国语文01.avi
德国语文02.avi
……
中国语文02.avi
中国语文01.avi
……
美国语文.avi
……
如上,R开头的日本在D开头的德国前面,Z开头的中国在M开头的美国的前面在德国的后面,中间还夹杂了其他国别的课件,根本不按0~9和A~Z的顺序排序。教师通过网络播放机很难直观便捷地选择所需课件,使用上有所不便。
这用起来就很别扭,有点被外人强迫使用他们的文化习惯,而被迫改掉自己的固有的文化习惯一样的被歧视感。
2013年4月24日 12:58 | # | 引用
弓中發 说:
Unicode是按照漢字部首排序的,這是最經典的字典序,康熙字典就是這樣排的。Unicode要照顧到臺灣、日本、韓國、越南,怎麼能用拼音排序?不要把自己想成天朝上國,那跟閉關鎖國的清朝人是一個心態。
2013年6月 4日 23:14 | # | 引用
苏 说:
GBK 节约字节些.
2013年8月28日 11:34 | # | 引用
ff 说:
SB
2014年6月 6日 12:20 | # | 引用
二三 说:
通用不是问题,关键在话语权,GBK也是大部分兼容老外的英文。
应该简单的兼容复杂的,反之则不行。
2015年6月19日 23:37 | # | 引用
Rays 说:
都9102了,还有用非utf8的睿智?
2019年11月 2日 01:30 | # | 引用
哇哈哈 说:
这不是2008的文章吗
2019年11月21日 11:16 | # | 引用