
上一篇文章,我介绍了KMP算法。
但是,它并不是效率最高的算法,实际采用并不多。各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法。
Boyer-Moore算法不仅效率高,而且构思巧妙,容易理解。1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了这种算法。
下面,我根据Moore教授自己的例子来解释这种算法。
1.

假定字符串为"HERE IS A SIMPLE EXAMPLE",搜索词为"EXAMPLE"。
2.

首先,"字符串"与"搜索词"头部对齐,从尾部开始比较。
这是一个很聪明的想法,因为如果尾部字符不匹配,那么只要一次比较,就可以知道前7个字符(整体上)肯定不是要找的结果。
我们看到,"S"与"E"不匹配。这时,"S"就被称为"坏字符"(bad character),即不匹配的字符。我们还发现,"S"不包含在搜索词"EXAMPLE"之中,这意味着可以把搜索词直接移到"S"的后一位。
3.

依然从尾部开始比较,发现"P"与"E"不匹配,所以"P"是"坏字符"。但是,"P"包含在搜索词"EXAMPLE"之中。所以,将搜索词后移两位,两个"P"对齐。
4.
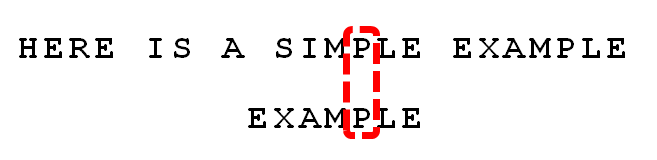
我们由此总结出"坏字符规则":
后移位数 = 坏字符的位置 - 搜索词中的上一次出现位置
如果"坏字符"不包含在搜索词之中,则上一次出现位置为 -1。
以"P"为例,它作为"坏字符",出现在搜索词的第6位(从0开始编号),在搜索词中的上一次出现位置为4,所以后移 6 - 4 = 2位。再以前面第二步的"S"为例,它出现在第6位,上一次出现位置是 -1(即未出现),则整个搜索词后移 6 - (-1) = 7位。
5.

依然从尾部开始比较,"E"与"E"匹配。
6.
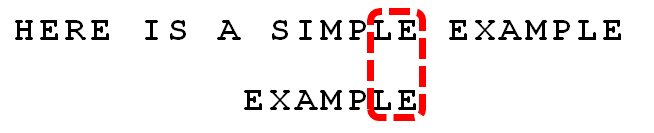
比较前面一位,"LE"与"LE"匹配。
7.
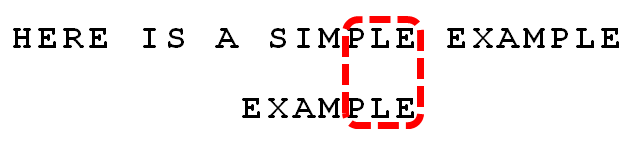
比较前面一位,"PLE"与"PLE"匹配。
8.

比较前面一位,"MPLE"与"MPLE"匹配。我们把这种情况称为"好后缀"(good suffix),即所有尾部匹配的字符串。注意,"MPLE"、"PLE"、"LE"、"E"都是好后缀。
9.
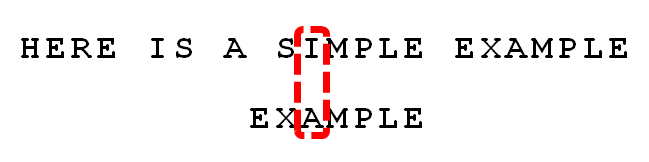
比较前一位,发现"I"与"A"不匹配。所以,"I"是"坏字符"。
10.
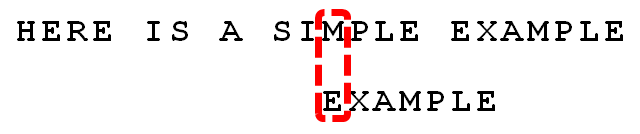
根据"坏字符规则",此时搜索词应该后移 2 - (-1)= 3 位。问题是,此时有没有更好的移法?
11.
我们知道,此时存在"好后缀"。所以,可以采用"好后缀规则":
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
举例来说,如果字符串"ABCDAB"的后一个"AB"是"好后缀"。那么它的位置是5(从0开始计算,取最后的"B"的值),在"搜索词中的上一次出现位置"是1(第一个"B"的位置),所以后移 5 - 1 = 4位,前一个"AB"移到后一个"AB"的位置。
再举一个例子,如果字符串"ABCDEF"的"EF"是好后缀,则"EF"的位置是5 ,上一次出现的位置是 -1(即未出现),所以后移 5 - (-1) = 6位,即整个字符串移到"F"的后一位。
这个规则有三个注意点:
(1)"好后缀"的位置以最后一个字符为准。假定"ABCDEF"的"EF"是好后缀,则它的位置以"F"为准,即5(从0开始计算)。
(2)如果"好后缀"在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,"EF"在"ABCDEF"之中只出现一次,则它的上一次出现位置为-1(即未出现)。
(3)如果"好后缀"有多个,则除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。比如,假定"BABCDAB"的"好后缀"是"DAB"、"AB"、"B",请问这时"好后缀"的上一次出现位置是什么?回答是,此时采用的好后缀是"B",它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个"好后缀"只出现一次,则可以把搜索词改写成如下形式进行位置计算"(DA)BABCDAB",即虚拟加入最前面的"DA"。
回到上文的这个例子。此时,所有的"好后缀"(MPLE、PLE、LE、E)之中,只有"E"在"EXAMPLE"还出现在头部,所以后移 6 - 0 = 6位。
12.
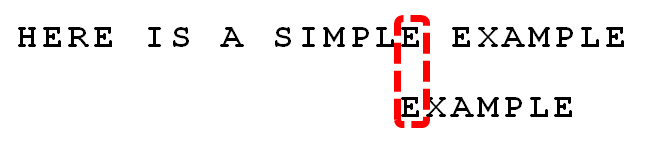
可以看到,"坏字符规则"只能移3位,"好后缀规则"可以移6位。所以,Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。
更巧妙的是,这两个规则的移动位数,只与搜索词有关,与原字符串无关。因此,可以预先计算生成《坏字符规则表》和《好后缀规则表》。使用时,只要查表比较一下就可以了。
13.
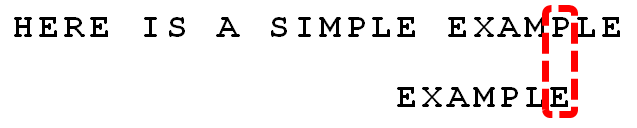
继续从尾部开始比较,"P"与"E"不匹配,因此"P"是"坏字符"。根据"坏字符规则",后移 6 - 4 = 2位。
14.

从尾部开始逐位比较,发现全部匹配,于是搜索结束。如果还要继续查找(即找出全部匹配),则根据"好后缀规则",后移 6 - 0 = 6位,即头部的"E"移到尾部的"E"的位置。
(完)

MGhostSoft 说:
本科的时候看算法课本就这里不明白,现在终于弄懂了。
2013年5月 3日 13:58 | # | 引用
zhiyelee 说:
太赞了,看了上一篇意犹未尽。
2013年5月 3日 14:06 | # | 引用
Bingfei 说:
通俗易懂的解释,如果教科书能按照这样编写,计算机会更有趣一些。
2013年5月 3日 14:18 | # | 引用
Will Shen 说:
受教了,阮兄每篇都很值得我輩細讀。
2013年5月 3日 15:08 | # | 引用
t.k. 说:
我也受教了,不过我想知道下面两处的来源:
1.文本编辑器的"查找"功能大多采用Boyer-Moore算法。
2.Boyer-Moore算法效率高于KMP。(KMP的时间复杂度是 O(n + k),但是Boyer-Moore是多少呢?)
2013年5月 3日 15:40 | # | 引用
bluesleaf 说:
阮兄,
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
计算时,位置的取值以"好后缀"的最后一个字符为准。
这里 "好后缀"的最后一个字符 不就只会是搜索词的最后一个字符吗?也就是说公式里的 好后缀的位置 就是 搜索词的长度-1(因为从0开始编号) 吧?
2013年5月 3日 16:24 | # | 引用
funnyfan 说:
“好后缀的位置”和“搜索词中的上一次出现位置”这两个我总是会弄混。。。
2013年5月 3日 16:38 | # | 引用
HCocoa 说:
“搜索词中的上一次出现位置”这个博主没解释清楚
2013年5月 3日 16:45 | # | 引用
阮一峰 说:
可以参见这个链接。
2013年5月 3日 18:49 | # | 引用
阮一峰 说:
我加了两个例子,是不是好一点了?
2013年5月 3日 19:02 | # | 引用
一个程序员 说:
学习了,想到一个问题,如果从后面往前找这个算法该如何实现呢,规则还一样吗?
2013年5月 3日 20:31 | # | 引用
MaskRay 说:
有效Boyer-Moore algorithm實現的難點在于好後綴的計算,樸素的方法時間復雜度是O(m^2)的,O(m)的計算還需要用到Manacher algorithm。
2013年5月 3日 21:10 | # | 引用
biaobiaoqi 说:
另外,请教阮老师,贵博客的留言系统是自己做的定制开发还是用了哪个第三方的系统?感觉交互上比市面上常见的友言要好。多谢指导;)
2013年5月 3日 21:12 | # | 引用
ChanneW 说:
确实相当的巧妙!
2013年5月 3日 21:28 | # | 引用
xx 说:
此时,所有的"好后缀"(MPLE、PLE、LE、E)之中,只有"E"在"EXAMPLE"之中出现两次,所以后移 6 - 0 = 6位。
所以个啥?
觉得英文版更清楚
2013年5月 3日 21:32 | # | 引用
雪月秋水 说:
要是在来一篇字符串模糊匹配算法就好了~
2013年5月 3日 21:44 | # | 引用
sss 说:
看得感觉还不是特别懂..................
说一下 "3."这张图的到"4."这一步计算我的理解
以"3."为例
坏位置为重"example"对应的长字符串从后面开始查找,与上面位置对应不匹配的字第一次出现的位置.
比如图"3."以为例,经过前面的位移后,"example"的最后一位"e"对应长字符串的"p";
因为p != e;所以:
坏位置 = "example"中"e"的位置(也就是6)
但是p在"example",所以:
搜索词中的上一次出现位置 = p在"example"中的位置(也就是4)
不知道我的理解是否正确?
2013年5月 3日 21:59 | # | 引用
hejianchao 说:
同求:字符串模糊匹配算法
2013年5月 3日 22:01 | # | 引用
Onyas 说:
看了楼主两篇文章受益匪浅,,之前看了好多关于KMP与BM的文章和书都是一知半解,楼主解释的很清晰,,不知啥时候写下KMP和BM的实现,,网上许多写的都乱七八糟的
2013年5月 3日 22:49 | # | 引用
hancy 说:
阮老师写的真好。
看的过程中只有一点迷糊了下:所有的"好后缀"(MPLE、PLE、LE、E)之中,是先选最长的“好后缀”MPlE,去找它在"搜索词中的上一次出现位置",没有才选短一点的PLE,以此类推,直到最短的好后缀?是这样吧?
2013年5月 4日 10:21 | # | 引用
阮一峰 说:
@hancy:
对,就是这样。
因为“好后缀规则”比较麻烦,有些实现就只部署“坏字符规则”。
2013年5月 4日 12:15 | # | 引用
adam 说:
这个算法设计比较精巧。
看阮兄的一系列文章,收益匪浅,尤其是《TF-IDF与余弦相似性的应用》系列,让大家明白其实算法和实际应用结合后,并不是那么的令人生畏。
2013年5月 4日 15:31 | # | 引用
花生 说:
关于坏字符的上一次位置,可能让人不理解。
上一次位置:如果有多个坏字符,指搜索词的最后一个坏字符的位置。这样是不是好点?
2013年5月 5日 15:12 | # | 引用
花生 说:
关于好后缀,如果有多个好后缀,则选择位于搜索词的头部,即第0位的那个,否则就是-1,我是这样理解的。
“除了最长的那个"好后缀"”,这句有点不理解。
2013年5月 5日 15:26 | # | 引用
Randoms 说:
这个怎么和linuxeden开源社区新浪微博上的文章是一样的。
2013年5月 5日 17:53 | # | 引用
shunner 说:
也是关于“上一次出现位置”。我想可不可以当作“最后一次出现位置”?
以“坏字符”为例,就是在搜索词里从后往前找到的第一个“坏字符”的位置。这在搜索词中包含多个“坏字符”时,能够保证不会后移太多。
2013年5月 5日 18:39 | # | 引用
navono 说:
坏字符规则表和《好后缀规则表怎么生成?
它们都要根据字符在搜索词中出现的位置,怎么说和原字符(被搜索词?)无关?
2013年5月 7日 08:57 | # | 引用
navono 说:
2013年5月 7日 09:54 | # | 引用
freeboy1015 说:
坏字符规则中如何算出后移的位数呢?我在开源中国博客(http://www.oschina.net/question/12_23429)中看到了计算坏字符移动数组BmBc的方法:
"BmBc数组的定义,分两种情况。
1、 字符在模式串中有出现。如下图,BmBc[‘k’]表示字符k在模式串中最后一次出现的位置,距离模式串串尾的长度。
我对这个也有疑惑:情况1中为什么BmBc[‘k’]是表示字符k在模式串中最后一次出现的位置,距离模式串串尾的长度。如果有多个k出现呢?
假设:
T:abcdbccg
P: abcdbecg
现在c和e不匹配,按照你的上面的方法计算的BmBc[‘c’]等于1,显然不对啊!
2013年5月 7日 17:20 | # | 引用
freeboy1015 说:
我觉得定义靠谱点,开源中国这篇将BM的代码你看了没,我觉得计算坏字符的上一次位置数组的代码有问题(如果这个字符重复多次的话,它取的是最靠右的那个位置的)。
2013年5月 7日 17:26 | # | 引用
楚轩 说:
2013年5月 9日 08:36 | # | 引用
sea 说:
这个bm算法的好后缀部分和kmp算法的前缀函数一模一样吧?
猜测:bm算法是在kmp算法基础上发展的,而且效率略高。
2013年5月16日 13:01 | # | 引用
jihite 说:
阮老师 太厉害了, 新的偶像诞生了!
2013年8月29日 10:33 | # | 引用
francis 说:
有个地方想的不是很明白
12 里面说,“ Boyer-Moore算法的基本思想是,每次后移这两个规则之中的较大值。”
您能举个例子说明一下“坏字符规则”移位更大的情况吗?
谢谢了
2013年9月23日 13:09 | # | 引用
jimshao 说:
BM算法不是最高效的,还可以提升,关键是第二步,如果是坏字符,BM算法是从下一个字母开始,如果是个好后缀,则要做适当的平移。实际无论是否是好后缀还是坏后缀,下一个字符都得参与下一次匹配,所以可以从下一个字符开始匹配,本例中下一个字符是个空格,显然是个坏字符,则第二次从字符A开始,最后一位不匹配,再看下一个字母E,则做平移,以此类推。显然会比BM算法更高效。
2013年10月 4日 19:57 | # | 引用
kangzj 说:
得把“好后缀”和“上一次出现位置”的定义说明白吧,阮大
2013年10月 8日 17:12 | # | 引用
laigus 说:
我想知道坏字符规则怎么预处理
我还看过是bmbc['k']取离结尾最长的,也就是第一个出现的
但不管哪种都不符合“上一次出现的位置”
也就是说 对于一个字符'k',bmbc['k']与它不匹配的位置也有关,那么一个一维数组就能解决这个问题么?
2013年10月 9日 21:58 | # | 引用
CK 说:
好后缀是不是有些问题。按照文中说法,好后缀的位置就是:
最后一个字符的位置-最后一个位置的字符在匹配字符中出现的位置。
比如匹配字符是 errtert,它的好后缀无论怎么样都是:6-3=3.
2013年10月22日 23:09 | # | 引用
cumirror 说:
讲得真好,将整个算法的匹配思路讲得淋漓尽致,谢谢~
2013年11月 5日 10:21 | # | 引用
KG 说:
认真看了两遍,才算是领悟到了要领。楼主解释清晰透彻!
2013年12月27日 15:22 | # | 引用
宋小北 说:
讲的很赞哦,最常用的东西,还有这么多奥妙
2014年5月30日 16:31 | # | 引用
purh 说:
很赞,不知楼主能否写一篇sunday算法
2014年7月24日 09:19 | # | 引用
TargetNull 说:
怎么会有多个坏字符呢,你说的是不是好字符?比如ABCCCCDAB,那么好字符显然应该是AB而不是你说的最后一个B,我觉得博主讲的在前面补全的方法很好。
2014年8月29日 19:09 | # | 引用
yy57 说:
好后缀这个地方有点没看懂。
如果好后缀不是一个字母,那么好后缀肯定不止一个对吧。
比如举例说的MPLE,好后缀有MPLE,PLE,LE,E。
但是取哪个后缀进行计算的时候没说清楚,我感觉。
是先看,次长后缀是不是出现在词头,没有,再看次之的,以此类推么????
如果,所有的好后缀都没有出现在词头,那怎么办???
求解释。。。这个地方没看太懂,不过还是谢谢了!
说的挺透彻的!
2014年9月21日 21:48 | # | 引用
mkdym 说:
【(1)"好后缀"的位置以最后一个字符为准。假定"ABCDEF"的"EF"是好后缀,则它的位置以"F"为准,即5(从0开始计算)。】
那么无论是什么搜索词,好后缀的位置一定是(搜索词的长度-1)了?
2014年10月25日 10:27 | # | 引用
KJ 说:
不是"后移位数",而应该是“移后子首所在位置”
2015年4月 9日 12:43 | # | 引用
KJ 说:
我觉得博主没有把这个算法的核心思想表达出来。其实根本就没有多个好后缀,只有一个好后缀,那就是已经匹配的那个后缀。
其实他和尝试寻找坏字符的在待查找词中最后出现位置的思想是一模一样的:坏字符在尝试寻找一个可以和他吻合的点,然后与其结合匹配,以此来为他的妈妈,即带查找词,重新定位一个可能的匹配位置。
而坏字符串(已经匹配的那一段)也是一样的,他们也在寻找一段和他们吻合的位置,以此来重新定位他妈的位置。根本没有多个而是虚拟的将它们往前移动而已。
这两者的本质思想都是用妈妈身体上已知的信息,来重新定位。其实是不是好后缀根本不重要,只要他们在妈妈身上已经有了信息(就像坏字符表一样)那么就可以利用已经知道的信息来探求适合的位置。
那为什么要用到好后缀呢。其实不是这样的,是因为只有好后缀的信息妈妈才知道,才能被利用。
2015年4月 9日 13:56 | # | 引用
小火炉 说:
没明白《坏字符规则表》和《好字符规则表》是怎么生成的,那些数字是怎么计算出来的?难道是一步步比较出来的??还是不会啊。。明晚就要考试了,,,可以马上回复我吗?谢谢啦。
2015年7月 8日 19:16 | # | 引用
吴杰 说:
通熟 易懂 !
2015年7月22日 17:52 | # | 引用
左德军 说:
请问这个理解了吗?我现在还不太理解
2015年8月20日 10:50 | # | 引用
一只小白 说:
利用好后缀规则比较过之后应该先比较好后缀的前面还是后面呢
2015年10月20日 20:45 | # | 引用
rooeye 说:
阮老师的博客通俗易懂而又不失深度,怒赞!
2015年12月31日 11:18 | # | 引用
顽石 说:
看图8,搜索词为"EXAMPLE",已经匹配的为:MPLE,那么好后缀为MPLE、PLE、LE、E,按以下步骤处理:
1)在搜索词"EXAMPLE"里从右往左寻找下一个MPLE,如果存在按寻找的位置处理
2)如果不存在,依次在搜索词"EXAMPLE"的头部(最左边)匹配PLE、LE、E
2016年2月 4日 16:13 | # | 引用
Alex 说:
阮兄受教了,讲解的非常容易理解,我实现了一个C++版本:http://blog.csdn.net/honkhat/article/details/51014720
2016年3月30日 15:30 | # | 引用
cdreds 说:
阮老师讲的很清楚,但是有个地方还是有些疑问:“如果综合考虑坏字符和好后缀可能产生遗漏匹配的情况”
-----------------------------------
设:T="abcabababccc" P="abab"
-----------------------------------
第一步:
abcabababccc
abab
a不等于b,P向右移动1位
-----------------------------------
第二步:
abcabababccc
-abab
c不等于b,存在好后缀"ab"
利用坏字符,向右移动2位
利用好后缀,向右移动4位
取最大的移动4位
-----------------------------------
第三步:
abcabababccc
-----abab
观察字串,发现有遗漏的匹配
所以此时应该移动2位
-----------------------------------
abcabababccc
---abab
不清楚是怎么回事
2016年4月21日 18:07 | # | 引用
夜幕下的猫 说:
这里的坏字符、好后缀的算法都完全没有讲清楚。拿好后缀来说,前提是按照:
“搜索词中的上一次出现位置”
来计算。
举例:ABACA,好后缀有 ACA, CA, A,那么按照你的逻辑:
ACA = -1, CA = -1。
但是 A 呢?出现了两次,一次 A = 0,一次 A = 2,取哪个?根本没说清楚取哪个,这种情况咋整?
如果按照“搜索词中的上一次出现位置”的取法,那么 A = 2。这样就完全错了,随便举个例子:
文本:BCACABACA
子串:ABACA
如果取 A = 2,则 shift = 4 - 2 = 2,即后移 2 位,显然不是最优,这里后移 4 位,即取 A = 0 才是最优。
那么到此,坏字符、好后缀(包括那三个注意点),都没有描述清楚,如果按照这个去实现算法,出大问题。
2016年4月22日 13:32 | # | 引用
夜幕下的猫 说:
@KJ:
说的很对,实际上“好后缀”不是一张表,而是一个整数值,不同的 pattern 计算一次即可。
而“坏字符”则是 key-value pairs,用于快速查询。
文章并没有说清楚。
2016年4月22日 14:53 | # | 引用
夜猫 说:
@夜幕下的猫:
文中说了你这个ACA在串头补全(AC)ABACA, 所以应该是ACA=5-1=4,这才是这个好后缀应该移动的长度
2016年9月27日 10:06 | # | 引用
GOODIT.zhu 说:
确实就是!
2016年11月 9日 14:49 | # | 引用
GOODIT.zhu 说:
@cdreds:
不存在你所说的问题的!
利用好后缀,向右移动的也是2位,请参考上述“好后缀规则的三个注意点”中的1和3,尤其是1,
针对注意点1,可得出:‘abab’的好后缀‘ab’的位置=3;
针对注意点3,可得出:‘abab’的好后缀‘ab’在搜索词中第一次出现的位置=1
根据好后缀公式:后移位数 = 好后缀的位置 - 搜索词中的第一次出现位置,得:后移位数 = 3 - 1 = 2;
为什么我将阮老师的“搜索词中的上一次出现位置”表述成“搜索词中的第一次出现位置”呢?我想这才是阮老师想要表达的’上一次‘的含义;
2016年11月 9日 15:08 | # | 引用
没有剥皮的洋葱 说:
有不明白的知识google时,讲解的最清楚的总是阮老师的博客!以后先到这里看一下好了
2017年5月15日 16:21 | # | 引用
iandy2233 说:
中文能提前生成坏字符和好后缀表吗?
2017年6月29日 08:54 | # | 引用
无处自由 说:
这个帖子和那个介绍kmp算法的帖子一样,优点是把基本原理介绍得比较通俗易懂,但是一些重要的细节却没提到,所以价值大减。推荐这个帖子:http://blog.jobbole.com/52830/ 虽然有的表述不够精确,但总的来说还是解释得比较清楚。
2017年8月 4日 06:25 | # | 引用
cymurs 说:
@cdreds:
因为第二步中,好后缀的移动位数计算有误:
ab作为好后缀,它出现在搜索词头部,按照b来计算:3(好后缀中b的位置)-1(头部b的位置)=2,所以好后缀也是向右移动2位,跟坏字符的移动位数相同。
——————————————战狼2正在热映——分割线-----------------------
看到最近的留言是17年8月4日,说明时至今日依然有人在这里获益,依然能激起围观者的切磋研究,也说明真的是经典!!!
阮兄经常只用寥寥数语,就能把一些高难度理论讲解得鞭辟入里,入木三分,很厉害!所以,这么久以来,“阮一峰”也成了一种品质的保证。正如选C++书籍,有 侯捷 著作,就感觉一定是精品,一定会情不自禁的一探究竟。
2017年8月 7日 21:04 | # | 引用
刘毅 说:
阮老师写的真是好,关于其中的具体细节可以参考:http://www.61mon.com/index.php/archives/210/
2017年8月 9日 15:33 | # | 引用
王念一 说:
《坏字符规则表》需要动态计算:
假设字符串 "A0A1A",
在 1 处取上一次 'A' 出现位置,取到下标为 2,而在 0 处取则取到 0。
2017年8月22日 17:35 | # | 引用
Jasperyang 说:
11.(3)的规则讲的有点不对吧,如果字符串QQQQBABCDAB,匹配串是BABCDAB,则应该跳到第二个B的位置而不是第一个B的位置。
2017年11月21日 22:24 | # | 引用
cqh 说:
第9步,到第10步
I是坏字符,且,不在EXAMPLE中。
所以第10 步的图,EXAMPLE应该在I的后面一位。
根据2-3得出的。不知道我又没有说错。
2017年11月24日 19:43 | # | 引用
刘毅 说:
可以看看我分析的这篇,https://subetter.com/articles/2018/06/boyer-moore-algorithm.html
2018年7月11日 19:22 | # | 引用
good 说:
I"与"A"那个地方,好像搜索词少移了一位吧!
2018年10月30日 11:54 | # | 引用
狒狒 说:
我有一个疑问,可以帮我看一下吗:
如:
T = "ACDAABCDABCDEF"
P = "CDABABCD"
这时的“好后缀”是"CD"的话,
按照:
后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置
那么得到后移位数 = 7 - 1 = 6
实际后移6位就错过了正确的匹配。
如果好后缀不为“CD”的话,那么这种情况的好后缀是什么呢?
2018年12月25日 15:36 | # | 引用
Fred 说:
阮老师讲的没错,我补充一下下,文中“除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。”这句挺重要,“假如是最长的那个"好后缀",则上一次出现位置就不是必须是头部。”如:假定"CDABCDAB"的"好后缀"是"DAB"、"AB"、"B",由于DAB是最长后缀,这时"好后缀"的上一次出现位置是第3位,移位为7-3=4位,显然DAB不在头部。当然,除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。大家自己画下图就好理解了。
另外这是我转载阮老师的:https://blog.csdn.net/a3192048/article/details/87905388
2019年4月 4日 13:33 | # | 引用
小白帽 说:
阮老师的讲解还是很经典的,语言精练,从中明白了很多,只是存在两个疑问,我把评论一一看完,大部分的道友都是这个问题:
1.好后缀的移位问题:
如:假定"CDABCDAB"的"好后缀"是"DAB"、"AB"、"B",由于DAB是最长后缀,这时"好后缀"的上一次出现位置是第3位,移位为7-3=4位,显然DAB不在头部。问题来了:【当然,除了最长的那个"好后缀",其他"好后缀"的上一次出现位置必须在头部。】如:好后缀‘AB’,显然头部是没有可匹配的,那不就是后移整个模式串了吗?,正确的操作不是应该将前面的‘AB’后移到尾处吗?
【】内的内容是问题!
有哪位道友能讲一下?
2019年4月 8日 20:54 | # | 引用
后天下午算法求保佑 说:
http://yaowhat.com/2014/08/15/week-str-bm.html
2019年6月21日 19:48 | # | 引用
LZSho 说:
真是厉害,一下子就解释清楚了,至于细节如何实现反而相对没那么重要了,因为对于初学者跨过初步解释清楚这道门槛就很不容易了。
我是从邓俊辉老师的MOOC课过来的,邓老师的MOOC课和书本其他地方都说的很细致很通俗,例子也很多,反而到了“串”这一部分相对难的部分例子变少了,也没那么通俗了,不直观,搞得一头雾水。《算法4》我也看了,举的例子不够细致,更加懵。
2019年11月23日 20:01 | # | 引用
BillCool 说:
有相关的代码吗?比如如何构建上诉两个 坏字符、好后缀的代码???
2019年12月19日 13:39 | # | 引用
程序狗 说:
为什么说坏字符规则和好后缀规则只与模式串有关呢?不应该与坏字符有关么?
2020年5月28日 17:44 | # | 引用
userkang 说:
太强了,看了好几篇都看不下去,这篇简洁明了,秒懂,请问这玩意儿怎么评论,我要赞爆作者!
2020年10月12日 09:57 | # | 引用
xpro 说:
如果像abzabzab,这种 ab 好后缀出现了多次呢?按照第二个来么,出现的位置是 4?
2021年3月31日 17:24 | # | 引用
xpro 说:
@bluesleaf:
我也感觉是好后缀的位置就是搜索词末尾的索引,也就是 len(搜索词)-1
2021年3月31日 17:29 | # | 引用
NASA 说:
"我们还发现,'S'不包含在搜索词'EXAMPLE'之中,这意味着可以把搜索词直接移到'S'的后一位。"
初学者想问是怎么判断EXAMPLE中没有'S'的呢
2021年4月 5日 12:12 | # | 引用
ARCTURUS 说:
坏字符如果在模式串中出现多次, "上一次出现的位置"是指从前往后数还是从后往前呢
2022年3月16日 11:33 | # | 引用
chirsz 说:
文中的示意图是用 CSS 实现的,好厉害~
2022年6月23日 13:35 | # | 引用
谷禾水 说:
本人不才,将BM算法拆解为几个场景并用动画展示其过程。各位同学如果观看过程中发现动画有错误请通过邮件沟通指正,[email protected]。多谢。
BM算法场景一:坏字符场景且模式串中没有匹配字符 http://www.donghuasuanfa.com/platform/portal?pc=boyer-moore
BM算法场景二:坏字符场景且模式串中有匹配字符 http://www.donghuasuanfa.com/platform/portal?pc=boyer-moore-case2
BM算法场景三:好后缀场景且模式串中没有匹配字符 http://www.donghuasuanfa.com/platform/portal?pc=boyer-moore-case3
BM算法场景四:好后缀场景且模式串中有匹配字符 http://www.donghuasuanfa.com/platform/portal?pc=boyer-moore-case4
BM算法场景五:好后缀场景且模式串中有匹配子串后缀字http://www.donghuasuanfa.com/platform/portal?pc=boyer-moore-case5
2023年6月27日 15:19 | # | 引用