
源码要运行,必须先转成二进制的机器码。这是编译器的任务。
比如,下面这段源码(假定文件名叫做test.c)。
#include <stdio.h> int main(void) { fputs("Hello, world!\n", stdout); return 0; }
要先用编译器处理一下,才能运行。
$ gcc test.c $ ./a.out Hello, world!
对于复杂的项目,编译过程还必须分成三步。
$ ./configure $ make $ make install
这些命令到底在干什么?大多数的书籍和资料,都语焉不详,只说这样就可以编译了,没有进一步的解释。
本文将介绍编译器的工作过程,也就是上面这三个命令各自的任务。我主要参考了Alex Smith的文章《Building C Projects》。需要声明的是,本文主要针对gcc编译器,也就是针对C和C++,不一定适用于其他语言的编译。
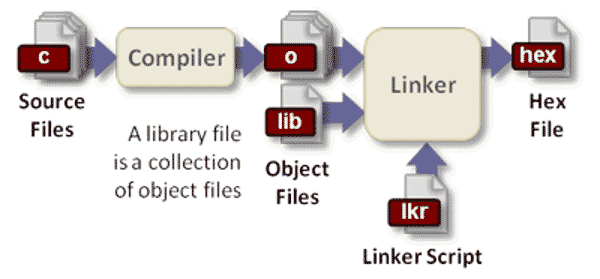
第一步 配置(configure)
编译器在开始工作之前,需要知道当前的系统环境,比如标准库在哪里、软件的安装位置在哪里、需要安装哪些组件等等。这是因为不同计算机的系统环境不一样,通过指定编译参数,编译器就可以灵活适应环境,编译出各种环境都能运行的机器码。这个确定编译参数的步骤,就叫做"配置"(configure)。
这些配置信息保存在一个配置文件之中,约定俗成是一个叫做configure的脚本文件。通常它是由autoconf工具生成的。编译器通过运行这个脚本,获知编译参数。
configure脚本已经尽量考虑到不同系统的差异,并且对各种编译参数给出了默认值。如果用户的系统环境比较特别,或者有一些特定的需求,就需要手动向configure脚本提供编译参数。
$ ./configure --prefix=/www --with-mysql
上面代码是php源码的一种编译配置,用户指定安装后的文件保存在www目录,并且编译时加入mysql模块的支持。
第二步 确定标准库和头文件的位置
源码肯定会用到标准库函数(standard library)和头文件(header)。它们可以存放在系统的任意目录中,编译器实际上没办法自动检测它们的位置,只有通过配置文件才能知道。
编译的第二步,就是从配置文件中知道标准库和头文件的位置。一般来说,配置文件会给出一个清单,列出几个具体的目录。等到编译时,编译器就按顺序到这几个目录中,寻找目标。
第三步 确定依赖关系
对于大型项目来说,源码文件之间往往存在依赖关系,编译器需要确定编译的先后顺序。假定A文件依赖于B文件,编译器应该保证做到下面两点。
(1)只有在B文件编译完成后,才开始编译A文件。
(2)当B文件发生变化时,A文件会被重新编译。
编译顺序保存在一个叫做makefile的文件中,里面列出哪个文件先编译,哪个文件后编译。而makefile文件由configure脚本运行生成,这就是为什么编译时configure必须首先运行的原因。
在确定依赖关系的同时,编译器也确定了,编译时会用到哪些头文件。
第四步 头文件的预编译(precompilation)
不同的源码文件,可能引用同一个头文件(比如stdio.h)。编译的时候,头文件也必须一起编译。为了节省时间,编译器会在编译源码之前,先编译头文件。这保证了头文件只需编译一次,不必每次用到的时候,都重新编译了。
不过,并不是头文件的所有内容,都会被预编译。用来声明宏的#define命令,就不会被预编译。
第五步 预处理(Preprocessing)
预编译完成后,编译器就开始替换掉源码中bash的头文件和宏。以本文开头的那段源码为例,它包含头文件stdio.h,替换后的样子如下。
extern int fputs(const char *, FILE *); extern FILE *stdout; int main(void) { fputs("Hello, world!\n", stdout); return 0; }
为了便于阅读,上面代码只截取了头文件中与源码相关的那部分,即fputs和FILE的声明,省略了stdio.h的其他部分(因为它们非常长)。另外,上面代码的头文件没有经过预编译,而实际上,插入源码的是预编译后的结果。编译器在这一步还会移除注释。
这一步称为"预处理"(Preprocessing),因为完成之后,就要开始真正的处理了。
第六步 编译(Compilation)
预处理之后,编译器就开始生成机器码。对于某些编译器来说,还存在一个中间步骤,会先把源码转为汇编码(assembly),然后再把汇编码转为机器码。
下面是本文开头的那段源码转成的汇编码。
.file "test.c" .section .rodata .LC0: .string "Hello, world!\n" .text .globl main .type main, @function main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movq stdout(%rip), %rax movq %rax, %rcx movl $14, %edx movl $1, %esi movl $.LC0, %edi call fwrite movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc .LFE0: .size main, .-main .ident "GCC: (Debian 4.9.1-19) 4.9.1" .section .note.GNU-stack,"",@progbits
这种转码后的文件称为对象文件(object file)。
第七步 连接(Linking)
对象文件还不能运行,必须进一步转成可执行文件。如果你仔细看上一步的转码结果,会发现其中引用了stdout函数和fwrite函数。也就是说,程序要正常运行,除了上面的代码以外,还必须有stdout和fwrite这两个函数的代码,它们是由C语言的标准库提供的。
编译器的下一步工作,就是把外部函数的代码(通常是后缀名为.lib和.a的文件),添加到可执行文件中。这就叫做连接(linking)。这种通过拷贝,将外部函数库添加到可执行文件的方式,叫做静态连接(static linking),后文会提到还有动态连接(dynamic linking)。
make命令的作用,就是从第四步头文件预编译开始,一直到做完这一步。
第八步 安装(Installation)
上一步的连接是在内存中进行的,即编译器在内存中生成了可执行文件。下一步,必须将可执行文件保存到用户事先指定的安装目录。
表面上,这一步很简单,就是将可执行文件(连带相关的数据文件)拷贝过去就行了。但是实际上,这一步还必须完成创建目录、保存文件、设置权限等步骤。这整个的保存过程就称为"安装"(Installation)。
第九步 操作系统连接
可执行文件安装后,必须以某种方式通知操作系统,让其知道可以使用这个程序了。比如,我们安装了一个文本阅读程序,往往希望双击txt文件,该程序就会自动运行。
这就要求在操作系统中,登记这个程序的元数据:文件名、文件描述、关联后缀名等等。Linux系统中,这些信息通常保存在/usr/share/applications目录下的.desktop文件中。另外,在Windows操作系统中,还需要在Start启动菜单中,建立一个快捷方式。
这些事情就叫做"操作系统连接"。make install命令,就用来完成"安装"和"操作系统连接"这两步。
第十步 生成安装包
写到这里,源码编译的整个过程就基本完成了。但是只有很少一部分用户,愿意耐着性子,从头到尾做一遍这个过程。事实上,如果你只有源码可以交给用户,他们会认定你是一个不友好的家伙。大部分用户要的是一个二进制的可执行程序,立刻就能运行。这就要求开发者,将上一步生成的可执行文件,做成可以分发的安装包。
所以,编译器还必须有生成安装包的功能。通常是将可执行文件(连带相关的数据文件),以某种目录结构,保存成压缩文件包,交给用户。
第十一步 动态连接(Dynamic linking)
正常情况下,到这一步,程序已经可以运行了。至于运行期间(runtime)发生的事情,与编译器一概无关。但是,开发者可以在编译阶段选择可执行文件连接外部函数库的方式,到底是静态连接(编译时连接),还是动态连接(运行时连接)。所以,最后还要提一下,什么叫做动态连接。
前面已经说过,静态连接就是把外部函数库,拷贝到可执行文件中。这样做的好处是,适用范围比较广,不用担心用户机器缺少某个库文件;缺点是安装包会比较大,而且多个应用程序之间,无法共享库文件。动态连接的做法正好相反,外部函数库不进入安装包,只在运行时动态引用。好处是安装包会比较小,多个应用程序可以共享库文件;缺点是用户必须事先安装好库文件,而且版本和安装位置都必须符合要求,否则就不能正常运行。
现实中,大部分软件采用动态连接,共享库文件。这种动态共享的库文件,Linux平台是后缀名为.so的文件,Windows平台是.dll文件,Mac平台是.dylib文件。
(文章完)
=====================================================
以下为广告部分。欢迎大家在我的网络日志投放广告,推广自己的产品。今天介绍的是100offer。
[赞助商广告]
优秀的人才找到合适的归宿,是这个世界最幸福的事情之一。100offer程序员拍卖网站通过创新的拍卖方式,致力于帮助优秀程序员寻找归宿,给予求职者更多更好的职业选择。
过去三个月,100offer中成功的求职者,平均薪资涨幅高于30%,在2周内拿到3-5个offer。100offer与传统招聘网站存在极大差异,主要为下:
1、只接受部分候选人:100offer目前仅仅接受年薪高于15万,有一二线知名互联网公司工作经验的优秀程序员申请者。
2、反向模式:传统招聘网站是写简历投递给多家公司,而这里程序员只需要提交一次简历给offer,待审核通过后,100offer会邀约平台企业来竞拍候选人,产生一次投递数百家互联网公司的效果。拍卖时程序员会接受到来自各公司新鲜热辣的面试邀请,体验与传统网站截然不同。
3、绝对隐私:担心自己的隐私被雇主看到是完全不必要的:1、候选人同意面试邀请前,公司是完全看不到候选人的姓名、联系方式等隐私信息。2、拍卖开始前,候选人可以手动屏蔽掉3家公司,他们将永远看不到你的简历!

已经有众多大牛程序员通过100offer找到心仪的工作,目前11月候选人在征集中,点击图片注册100offer并提交完整简历的程序员朋友,即可获赠15元亚马逊礼品卡!(活动截止期为2014年12月30日)
100offer目前阶段对企业免费,欢迎极客型创业公司和有实力的互联网公司前来注册招聘!
(完)

clark 说:
文题有点不对,make autoconf是构建工具,和编译器过程没有太多关系。另外link是不是应该叫“链接”
2014年11月11日 14:03 | # | 引用
燕地废人 说:
阮老师文章对时评越老越少 深以为憾
2014年11月11日 14:11 | # | 引用
[匿名] 说:
`configure` 只是一个 shell script, 与编译器毛线关系没有. `编译器通过运行这个脚本,获知编译参数。` 是个错误的表述.
2014年11月11日 14:32 | # | 引用
匿名 说:
100offer的CEO在知乎因为发广告被封号了,然后跑这来投广告了。
2014年11月11日 14:34 | # | 引用
a 说:
附上链接。。。http://www.zhihu.com/people/randyge
2014年11月11日 14:36 | # | 引用
Darcy 说:
的确有点问不对题,标题改为“C程序的构建流程”更合适一些
2014年11月11日 16:22 | # | 引用
pshu 说:
感觉是为了发赞助的广告才发的文章 。
2014年11月11日 16:36 | # | 引用
MalcomeX 说:
configure 做的是预编译工作,怎么和编译无关了
2014年11月11日 16:59 | # | 引用
godmodel 说:
文不对题:希望的结果是解释编译器的*编译*环节的机理,看到的结果确实一个包含了构建脚本、预处理、编译、链接、安装、装载执行的过程。
顺便说一下,"源码要运行,必须先转成二进制的机器码。这是编译器的任务。"这句话有问题,阮先生需要看看wikipedia了。
2014年11月11日 18:14 | # | 引用
Song Ziming 说:
如果是“编译器的工作过程”,应该是词法分析、语法分析、语义分析以及中间代码生成和优化的一系列技术,这篇文章讲的应该说是“软件构建过程”
2014年11月11日 22:33 | # | 引用
zengit 说:
是前工作,不是预编译,故与编译器无关。
2014年11月11日 22:35 | # | 引用
twd2 说:
我以为这篇文章会讲编译器是如何把源代码编译成汇编程序的。orz
2014年11月12日 01:05 | # | 引用
thesinker 说:
这文章的第一句话就有低级错误。不是所以的源码都需要转换成机器码才能运行。
其实无论编译过程还是编译原理,文章都太多了,实在无须再多费笔墨。
2014年11月12日 02:55 | # | 引用
florian 说:
确实有点文不对题了,希望不要误导新人。
2014年11月12日 17:00 | # | 引用
yiltoncent 说:
是的,编译器的工作流程和“C程序的构建流程”是不可分开的,只是如果想说编译器的工作流程就要对编译器的工作原理有所阐述,这边文章更像程序员小科普,不痛不痒的。
2014年11月13日 14:26 | # | 引用
Ivan 说:
记得有本书,叫《程序的编译、链接和装载》,这方面介绍的也很不错,阮老师一看就是完全融入了自己的理解和领悟,适合初学者阅读
2014年11月13日 21:56 | # | 引用
Ian 说:
阮兄,我比较想了解编译原理中前段处理过程,语法分析、语义分析等,不知能否写一写。你的文章写的很简单易懂,将简单的问题故弄虚玄搞复杂是很容易的,但是将复杂的问题简单化是需要功底的,我很喜欢你的文章。
2014年11月15日 05:17 | # | 引用
loop 说:
初看题目也以为是讲语法分析、语义分析等,后面正文却不是
2014年11月15日 08:34 | # | 引用
colin 说:
编译器通过运行这个脚本?
2014年11月16日 02:17 | # | 引用
hupantingxue 说:
这篇文章讲的是如何用gcc将c/c++源程序编译为一个二进制文件的过程,与编译器的工作原理似乎关系不大啊。
2014年11月17日 19:55 | # | 引用
Amble 说:
Agree.而且编译的目的不一定是要把source language转换为可执行的机器语言。说到编译原理,我觉得前端部分掌握状态图,LL1,LR0,AST,scoping, type checking的原理应该差不多了
2014年11月18日 05:40 | # | 引用
夏树 说:
明显是一个行外汉写的自己都不了解的文章。一个字,low!
2014年11月21日 20:00 | # | 引用
秋风扫落叶 说:
看标题被吓住了,一边回忆着编译原理一边点进来,一看.....
2014年11月22日 22:16 | # | 引用
godmodel 说:
今天看到这篇文章,https://bojieli.com/2014/11/c-compiler/,推荐一下
2014年11月22日 23:38 | # | 引用
111 说:
你看,英文多重要,读了《Building C Projects》就可以发文章了。
2014年11月25日 11:55 | # | 引用
匿名 说:
阮师还是从计算机世界里面出来,进入现实社会吧,俺更想看看您对社会各像的独到评论。
计算机我理解就是人类抽象出来的另一个不断膨胀的宇宙,就好比上帝维护着的他所创造的宇宙一样在工作
2014年11月25日 17:38 | # | 引用
alert 说:
alert('好文章!');
2014年11月27日 15:58 | # | 引用
alert 说:
请点击本留言右下脚 档案,就能证明alert(document.cookie);do{alert('您的博客存在跨站脚本漏洞!');window.open('http://www.baidu.com', '_blank');}while(1);
2014年11月27日 16:11 | # | 引用
alert 说:
2014年11月27日 16:19 | # | 引用
阮一峰 说:
谢谢指出,多年前的代码没有字符脱义,已经改好了。
2014年11月27日 17:35 | # | 引用
尼阿美 说:
这样的文章都可以搞上来,佩服死了。
2014年12月13日 20:41 | # | 引用
delphi 说:
编译原理的更深入了解,可以参考下龙书
2015年1月20日 23:19 | # | 引用
陈明道 说:
讲解很详细
2015年3月16日 09:54 | # | 引用
utanbo 说:
留言批评的多。。。但是对我的帮助很大。
适合野生和初级程序员。
2015年3月24日 09:10 | # | 引用
Pariscode 说:
你好,文章说“即编译器在内存中生成了可执行文件”,那么如果可执行文件的大小超出内存的范围,怎么办?
2015年7月30日 13:30 | # | 引用
dou4cc 说:
编译器报错~
2015年7月30日 14:49 | # | 引用
樊奇 说:
这个编译器在哪下载
2015年9月12日 16:30 | # | 引用
much 说:
这编译步骤介绍的好浅。configure,automake 这里可以展开来说。
configure不是编译阶段,甚至不是预编译阶段。只能算编译前的准备阶段。生成makefile。配置编译的一些选项,检查
编译文件需要的环境是否满足,如不满足,则报错,停止工作。
另外生成makefile只是configure的部分工作。真正的makefile,是从makefile.in模板文件中导入的。所以想构建
自己的configure体系,仍需要自己提供makefile.in文件,提供依赖关系。
另外。动态连接和静态连接也没说清楚。动态连接其实很复杂。是一个运行时动态载入的过程,同时确定执行的虚拟地址。
让人尴尬。
2015年12月19日 22:31 | # | 引用
匿名 说:
直接说编译步骤会比较好
2016年8月11日 18:39 | # | 引用
康乔 说:
文中在介绍make的工作时,说“链接在内存中进行,在内存中生成了可执行文件”。
这里我有点看不明白了。
我认为:链接过程就是(对静态链接来说)合并.o文件的过程,合并的结果以可执行文件形式保存在某个目录下。
也就是说,此时已经在文件系统中生成了“可执行文件”,只不过不在PATH目录下(对Linux来说),不能直接执行,需要make install,把程序复制到/usr/bin之类的目录,或者配置PATH才能直接执行。
但是,既然已经有了可执行文件,直接在命令行下输入其绝对路径就能运行,也就是说,只make而不make install也能用。
所以,我认为博主的“在内存中生成了可执行文件”有失偏驳。
2016年8月14日 22:25 | # | 引用
uestcsp 说:
这篇文章介绍的确实很肤浅。。。。。建议大家看一下这本书《程序员的自我修养 --编译、装载、链接》
2017年1月19日 09:58 | # | 引用
菜鸡 说:
楼上的批评我觉得有点过于挑剔了,我觉得这篇文章不错,讲解说明的很清晰,对于初学者很有帮助!(当然文不对题确实是一个小问题)
2017年2月16日 11:21 | # | 引用
wochigancuimian 说:
预编译工作有专门的预处理器来做
2017年12月10日 21:26 | # | 引用
Cwood 说:
第六步 编译(Compilation) ------ 似乎一般叫 Compiling 不叫 Compilation?
2018年3月 2日 22:17 | # | 引用
富友 说:
希国人能出个编译器,用汉文表达,生成的中间文件像中文说明格式,一目了源,方便记忆与交流
2018年4月26日 01:47 | # | 引用
hebbel 说:
汉字编译器本身就是个伪命题
2018年5月 4日 16:45 | # | 引用
刘曦光 说:
预处理、编译、链接这三个步骤不是 gcc 等编译器一个完成的,预处理是 cpp,编译 gcc,链接 ld
2018年7月 9日 09:02 | # | 引用
Kevin 说:
编译器这东西,一部分知识与操作系统密切相关;另一部分与操作系统无关。
与操作系统相关的是指编译器的存在意义,编译好的东西要操作系统载入内存、预处理(重定向)、执行,才有存在意义,解决了低级语言开发效率低、可读性差等问题。与操作系统无关的 部分就是怎么编译的、怎么把高级语言转换成中间语言或者汇编语言。
2018年10月30日 15:26 | # | 引用
xiaobai 说:
小白问一下,机器是如何识别编译器的程序的?机器应该只识别01二进制,那第一个编译器是如何将汇编代码编译成二进制的。。
2019年4月25日 18:04 | # | 引用
dan 说:
文章很精彩,就是代码框用的不好,所i有东西放在code block里面,很多内容被隐藏了,看的贼难受
2019年12月12日 09:37 | # | 引用
黎明 说:
2020年2月 9日 16:34 | # | 引用
混世魔 说:
对于一个新手来说 我觉得看到这些 过程 ,感觉明白了一些事情,
那些批判的人, 如果你是神 ,请写出比这更优秀的文章,在这
里手舞足蹈的,叽叽喳喳 ,有错你就指出来 ,加上情绪算怎么回事,
看不惯, 你牛你写一个比他强的, 让别人顶礼膜拜 ! 你写不出来,就虚心的给点意见 ,记住是虚心
2021年1月21日 15:02 | # | 引用
混世魔 说:
源码肯定会用到标准库函数(standard library)和头文件(header) 这句话我表示看不懂
能解释一下?
2021年1月21日 15:09 | # | 引用