
1.
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
举例来说,数值0x2211使用两个字节储存:高位字节是0x22,低位字节是0x11。
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
- 小端字节序:低位字节在前,高位字节在后,即以
0x1122形式储存。

同理,0x1234567的大端字节序和小端字节序的写法如下图。
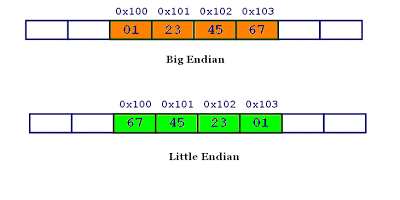
2.
我一直不理解,为什么要有字节序,每次读写都要区分,多麻烦!统一使用大端字节序,不是更方便吗?
上周,我读到了一篇文章,解答了所有的疑问。而且,我发现原来的理解是错的,字节序其实很简单。
3.
首先,为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
4.
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。
理解这一点,才能理解计算机如何处理字节序。
5.
字节序的处理,就是一句话:
"只有读取的时候,才必须区分字节序,其他情况都不用考虑。"
处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。
即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
6.
举例来说,处理器读入一个16位整数。如果是大端字节序,就按下面的方式转成值。
x = buf[offset] * 256 + buf[offset+1];
上面代码中,buf是整个数据块在内存中的起始地址,offset是当前正在读取的位置。第一个字节乘以256,再加上第二个字节,就是大端字节序的值,这个式子可以用逻辑运算符改写。
x = buf[offset]<<8 | buf[offset+1];
上面代码中,第一个字节左移8位(即后面添8个0),然后再与第二个字节进行或运算。
如果是小端字节序,用下面的公式转成值。
x = buf[offset+1] * 256 + buf[offset];
32位整数的求值公式也是一样的。
/* 大端字节序 */ i = (data[3]<<0) | (data[2]<<8) | (data[1]<<16) | (data[0]<<24); /* 小端字节序 */ i = (data[0]<<0) | (data[1]<<8) | (data[2]<<16) | (data[3]<<24);
(完)

ahern88 说:
挺好的,一直不清楚大端小端的作用
2016年11月22日 10:11 | # | 引用
bones7456 说:
原文链接需要 s/htm$/html/g 一下。
2016年11月22日 10:21 | # | 引用
islet8 说:
有一点没说清楚,为什么写不用关心大小端?既然写的时候不用关心,那么读的时候决定大小端的依据来自哪里?
2016年11月22日 11:00 | # | 引用
阮一峰 说:
@bones7456:谢谢指出,已经改正。
2016年11月22日 11:03 | # | 引用
业余草 说:
不错!如果在结合实例就更好了,来个demo,在程序中如何使用,岂不是完美!
2016年11月22日 11:07 | # | 引用
端序侠 说:
只有读取时需要连续读取超过一个字节数据时才需要考虑字节序问题。
2016年11月22日 11:20 | # | 引用
rednax 说:
“计算机的内部处理都是小端字节序”不正确……
虽然x86是小端的,不过也有很多CPU是大端的(比如powerpc)。另外小端虽然对加法器比较友好,但除法还是大端更合适,所以这种取舍其实只是一些历史问题吧……
2016年11月22日 12:24 | # | 引用
业余草 说:
@rednax:
恩恩,赞同,多谢指出
2016年11月22日 12:35 | # | 引用
carlxu 说:
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。
小端模式更适合系统内部,大端模式更适合网络数据传递,加上一些历史引领的原因,
导致现在两种字节序方式并存。
2016年11月22日 20:08 | # | 引用
zeke 说:
即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
这个有疑问,如果向外部设备写入数据不考虑字节序,那外部设备怎么知道数据是大端还是小端?
2016年11月23日 12:37 | # | 引用
四叶草日记 说:
赞一个,感谢大神分享!!!
2016年11月24日 09:48 | # | 引用
cccc 说:
请问能讲一下换行符的发展历史么?也就是/r/n之类的问题,还有utf-8的bom问题
2016年11月25日 15:11 | # | 引用
tripleW 说:
这就是驱动的作用了~~~
2016年11月26日 08:58 | # | 引用
李杰 说:
C++和Java做数据传输时,就会遇到字节序不一致的问题
2016年11月28日 18:05 | # | 引用
小码驹 说:
阮老师您好:
我是一名大三学生,一直再学js,是通过你的博客一步步学习js的。感觉您的博客非常好。但是我近期很迷茫,想提高js编程能力不知道从何下手。希望能得到您的指点
2016年11月28日 19:02 | # | 引用
Ts 说:
阮老师,http://es6.ruanyifeng.com/#docs/let#留言 es6 let和const命令这一章的不允许重复声明这一块代码图
// 报错
function () {
let a = 10;
var a = 1;
}
// 报错
function () {
let a = 10;
let a = 1;
}
好像忘记了为函数命名。
2016年11月29日 10:17 | # | 引用
seder 说:
写的挺好,学习了
2016年11月29日 13:08 | # | 引用
FrozenMap 说:
曾经拜读过你的SimpleHTTPServerWithUpload
2016年11月30日 16:47 | # | 引用
whuang 说:
写也要考虑字节序啦,比如发包时要填网络序。
另外在转发设备里,为了高效,即使在小段系统,有些数据也要用大端存储。
2016年12月 5日 13:44 | # | 引用
damon 说:
首先,为什么会有小端字节序?
答案是,计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。
这段内容有待斟酌,如 51单片机就是大端模式,另外很多 ARM 的 MCU 都是默认小端,且可以用户自己设置选用大端还是小端模式的。
2016年12月 6日 10:39 | # | 引用
Leland 说:
其次,不同系统选择的Endian也不尽相同,如MacOS就是Big Endian.
2016年12月21日 10:58 | # | 引用
杨彦朋 说:
最近一个Demo在使用Socket进行通信,Java客户端和C服务器端,数据包的传输统一采用Byte格式,不过java处理大端字节序,c处理小端字节序,看到这个转换方法,和具体的使用目的,还不错啊
2016年12月26日 12:41 | # | 引用
Donald 说:
"计算机电路先处理低位字节,效率比较高"
这个从何谈起?对于计算机,大小字节序没有效率的问题,这是个习惯问题。就像有人习惯用左手有人习惯用右手。
“计算机的内部处理都是小端字节序”
这个是错误的。早期的UNIX CPU都是用大字节。其实用小字节的CPU很少,是从x86开始。AMR可以大小字节切换,不过习惯是设成小字节的。
网络传输习惯用大字节是因为早期网络规则制定者IBM,DIGITAL等的CPU都是大字节的。这只是一个习惯,如果没有交互性的问题,比如是私有的协议,大小字节都没所谓。
2017年1月23日 07:07 | # | 引用
Donald 说:
程序中处理字节序不应该用文中的转换方法。当不知道当前cpu用什么字节序,像ARM这样可以切换字节序的CPU,这样的方法会得到错误的结果。
程序中不应该出现大小字节序的问题,只有“网络字节序”和“本机字节序”。应该使用ntohl,ntohs,htonl,htons进行转换。
2017年1月23日 09:42 | # | 引用
wade 说:
阮老师,最后举的32位的例子,写反了吧?刚好颠倒。
2017年2月15日 13:33 | # | 引用
王嘉成 说:
逻辑运算符 => 位运算符
2017年2月20日 14:52 | # | 引用
gibson 说:
/* 大端字节序 */
i = (data[3]
/* 小端字节序 */
i = (data[0]
楼住您好!
这两个字节序是不是写反了。。。
2017年3月 3日 11:55 | # | 引用
7heaven 说:
其实还有middle-endian
2017年3月 7日 18:45 | # | 引用
Digital 说:
这位朋友估计没搞过硬件。大小字节序的确有效率的问题,你自己拿逻辑门堆一个ALU就明白了。算加减乘除要从LSB到MSB进位。如果先把小位算完了再算大位,直接把carry out加到大位里就可以了,这个在8位CPU上尤其重要。当然现在的处理器已经极为复杂,这点优化已经没必要了,大小字节纯粹是为了向后兼容。
2017年3月 8日 12:44 | # | 引用
G0561 说:
不浮躁的一个人,赞你
2017年3月23日 20:12 | # | 引用
Donald 说:
这位朋友估计好久没搞过硬件了,还是停留在8位机的思维。32位的ALU信号从数据线过来只需要一个上升或下降缘。在处理器内部只有一种字节序,没有两种东西的比较问题。
2017年3月29日 21:48 | # | 引用
Jack Lin 说:
没错吧!
2017年6月 2日 11:23 | # | 引用
Jack Lin 说:
你们俩继续讨论,我不懂硬件,只能前排观看!
2017年6月 2日 11:24 | # | 引用
ming__ 说:
你的这句,“程序中不应该出现大小字节序的问题,只有‘网络字节序’和‘本机字节序’。应该使用ntohl,ntohs,htonl,htons进行转换"。我很受用,感觉一下子就掌握到了问题的本质,即在什么地方需要注意什么问题。
2019年4月28日 10:08 | # | 引用
路小鹿 说:
阿拉伯语也是从低地址开始读,再也不嫌弃它奇怪了~
2019年7月26日 00:39 | # | 引用