
本文要回答一个很重要的问题:函数式编程有什么用?
目前,主流的编程语言都不是函数式的,已经能够满足需求。为何还要学函数式编程呢,只为了多理解一些新奇的概念?

一个网友说:
"函数式编程有什么优势呢?"
"我感觉,这种写法可能会令人头痛吧。"
很长一段时间,我根本不知道从何入手,如何将它用于实际项目?直到有一天,我学到了 Pointfree 这个概念,顿时豁然开朗,原来应该这样用!
我现在觉得,Pointfree 就是如何使用函数式编程的答案。

一、程序的本质
为了理解 Pointfree,请大家先想一想,什么是程序?

上图是一个编程任务,左侧是数据输入(input),中间是一系列的运算步骤,对数据进行加工,右侧是最后的数据输出(output)。一个或多个这样的任务,就组成了程序。
输入和输出(统称为 I/O)与键盘、屏幕、文件、数据库等相关,这些跟本文无关。这里的关键是,中间的运算部分不能有 I/O 操作,应该是纯运算,即通过纯粹的数学运算来求值。否则,就应该拆分出另一个任务。
I/O 操作往往有现成命令,大多数时候,编程主要就是写中间的那部分运算逻辑。现在,主流写法是过程式编程和面向对象编程,但是我觉得,最合适纯运算的是函数式编程。
二、函数的拆分与合成
上面那张图中,运算过程可以用一个函数fn表示。

fn的类型如下。
fn :: a -> b
上面的式子表示,函数fn的输入是数据a,输出是数据b。
如果运算比较复杂,通常需要将fn拆分成多个函数。

f1、f2、f3的类型如下。
f1 :: a -> m f2 :: m -> n f3 :: n -> b
上面的式子中,输入的数据还是a,输出的数据还是b,但是多了两个中间值m和n。
我们可以把整个运算过程,想象成一根水管(pipe),数据从这头进去,那头出来。

函数的拆分,无非就是将一根水管拆成了三根。

进去的数据还是a,出来的数据还是b。fn与f1、f2、f3的关系如下。
fn = R.pipe(f1, f2, f3);
上面代码中,我用到了 Ramda 函数库的pipe方法,将三个函数合成为一个。Ramda 是一个非常有用的库,后面的例子都会使用它,如果你还不了解,可以先读一下教程。
三、Pointfree 的概念
fn = R.pipe(f1, f2, f3);
这个公式说明,如果先定义f1、f2、f3,就可以算出fn。整个过程,根本不需要知道a或b。
也就是说,我们完全可以把数据处理的过程,定义成一种与参数无关的合成运算。不需要用到代表数据的那个参数,只要把一些简单的运算步骤合成在一起即可。
这就叫做 Pointfree:不使用所要处理的值,只合成运算过程。中文可以译作"无值"风格。
请看下面的例子。
var addOne = x => x + 1; var square = x => x * x;
上面是两个简单函数addOne和square。
把它们合成一个运算。
var addOneThenSquare = R.pipe(addOne, square); addOneThenSquare(2) // 9
上面代码中,addOneThenSquare是一个合成函数。定义它的时候,根本不需要提到要处理的值,这就是 Pointfree。
四、Pointfree 的本质
Pointfree 的本质就是使用一些通用的函数,组合出各种复杂运算。上层运算不要直接操作数据,而是通过底层函数去处理。这就要求,将一些常用的操作封装成函数。
比如,读取对象的role属性,不要直接写成obj.role,而是要把这个操作封装成函数。
var prop = (p, obj) => obj[p]; var propRole = R.curry(prop)('role');
上面代码中,prop函数封装了读取操作。它需要两个参数p(属性名)和obj(对象)。这时,要把数据obj要放在最后一个参数,这是为了方便柯里化。函数propRole则是指定读取role属性,下面是它的用法(查看完整代码)。
var isWorker = s => s === 'worker'; var getWorkers = R.filter(R.pipe(propRole, isWorker)); var data = [ {name: '张三', role: 'worker'}, {name: '李四', role: 'worker'}, {name: '王五', role: 'manager'}, ]; getWorkers(data) // [ // {"name": "张三", "role": "worker"}, // {"name": "李四", "role": "worker"} // ]
上面代码中,data是传入的值,getWorkers是处理这个值的函数。定义getWorkers的时候,完全没有提到data,这就是 Pointfree。
简单说,Pointfree 就是运算过程抽象化,处理一个值,但是不提到这个值。这样做有很多好处,它能够让代码更清晰和简练,更符合语义,更容易复用,测试也变得轻而易举。
五、Pointfree 的示例一
下面,我们来看一个示例。
var str = 'Lorem ipsum dolor sit amet consectetur adipiscing elit';
上面是一个字符串,请问其中最长的单词有多少个字符?
我们先定义一些基本运算。
// 以空格分割单词 var splitBySpace = s => s.split(' '); // 每个单词的长度 var getLength = w => w.length; // 词的数组转换成长度的数组 var getLengthArr = arr => R.map(getLength, arr); // 返回较大的数字 var getBiggerNumber = (a, b) => a > b ? a : b; // 返回最大的一个数字 var findBiggestNumber = arr => R.reduce(getBiggerNumber, 0, arr);
然后,把基本运算合成为一个函数(查看完整代码)。
var getLongestWordLength = R.pipe( splitBySpace, getLengthArr, findBiggestNumber ); getLongestWordLength(str) // 11
可以看到,整个运算由三个步骤构成,每个步骤都有语义化的名称,非常的清晰。这就是 Pointfree 风格的优势。
Ramda 提供了很多现成的方法,可以直接使用这些方法,省得自己定义一些常用函数(查看完整代码)。
// 上面代码的另一种写法 var getLongestWordLength = R.pipe( R.split(' '), R.map(R.length), R.reduce(R.max, 0) );
六、Pointfree 示例二
最后,看一个实战的例子,拷贝自 Scott Sauyet 的文章《Favoring Curry》。那篇文章能帮助你深入理解柯里化,强烈推荐阅读。
下面是一段服务器返回的 JSON 数据。
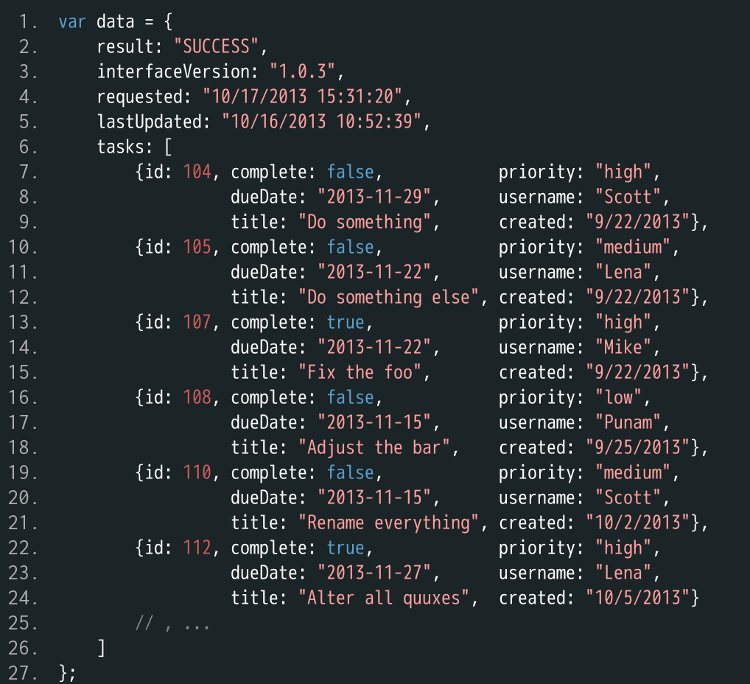
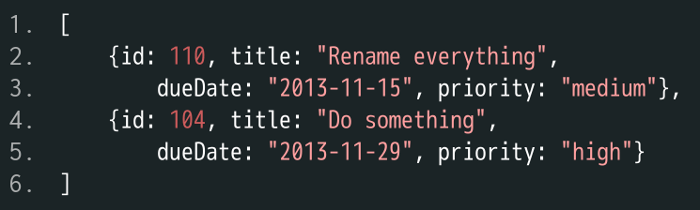
现在要求是,找到用户 Scott 的所有未完成任务,并按到期日期升序排列。
过程式编程的代码如下(查看完整代码)。
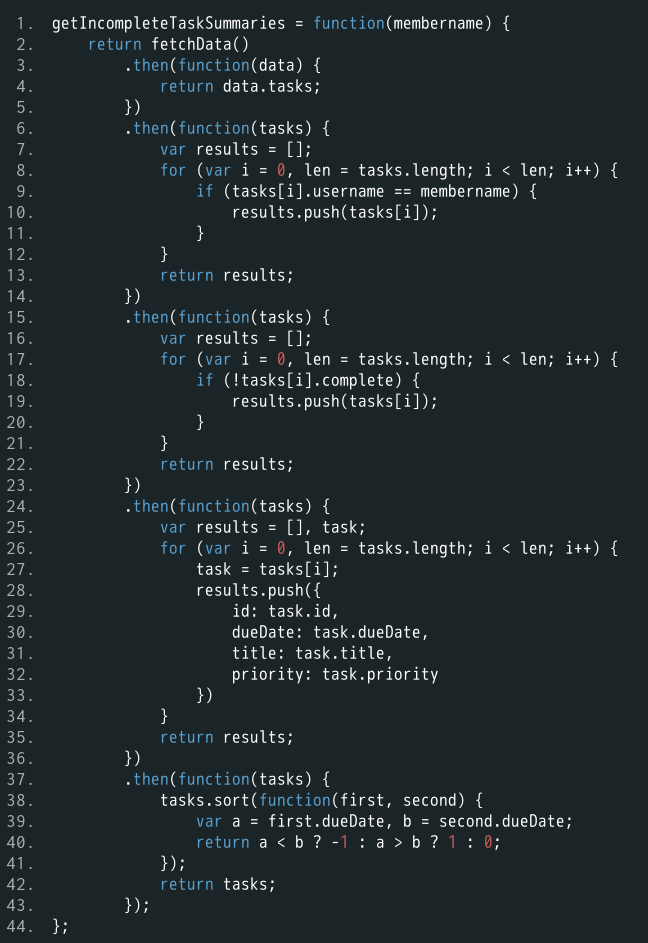
上面代码不易读,出错的可能性很大。
现在使用 Pointfree 风格改写(查看完整代码)。
var getIncompleteTaskSummaries = function(membername) { return fetchData() .then(R.prop('tasks')) .then(R.filter(R.propEq('username', membername))) .then(R.reject(R.propEq('complete', true))) .then(R.map(R.pick(['id', 'dueDate', 'title', 'priority']))) .then(R.sortBy(R.prop('dueDate'))); };
上面代码已经清晰很多了。
另一种写法是,把各个then里面的函数合成起来(查看完整代码)。
// 提取 tasks 属性 var SelectTasks = R.prop('tasks'); // 过滤出指定的用户 var filterMember = member => R.filter( R.propEq('username', member) ); // 排除已经完成的任务 var excludeCompletedTasks = R.reject(R.propEq('complete', true)); // 选取指定属性 var selectFields = R.map( R.pick(['id', 'dueDate', 'title', 'priority']) ); // 按照到期日期排序 var sortByDueDate = R.sortBy(R.prop('dueDate')); // 合成函数 var getIncompleteTaskSummaries = function(membername) { return fetchData().then( R.pipe( SelectTasks, filterMember(membername), excludeCompletedTasks, selectFields, sortByDueDate, ) ); };
上面的代码跟过程式的写法一比较,孰优孰劣一目了然。
七、参考链接
(完)

李冬杰 说:
解决了我的疑问,谢谢老师
2017年3月13日 07:57 | # | 引用
章鱼来 说:
每过一段时间回来翻翻阮老师的文章,收获巨大!
2017年3月13日 09:04 | # | 引用
szpzs 说:
谢谢阮老师,使得我更加理解函数式编程。
2017年3月13日 09:33 | # | 引用
czs 说:
柯里化确实使pointfree更加自然,感谢!
2017年3月13日 09:35 | # | 引用
任天缘 说:
有一种豁然开朗、拨云见日的感觉
2017年3月13日 09:53 | # | 引用
斑谷 说:
这个风格似乎不方便调试
2017年3月13日 10:01 | # | 引用
黄亮 说:
每每阅读阮老师的文章,感觉都收获巨大
2017年3月13日 10:30 | # | 引用
RedNax 说:
并没有觉得这个解释了“函数式编程有什么用”,只是解答了“函数式编程怎么用”……
2017年3月13日 10:41 | # | 引用
业余草 说:
函数式编程是一种编程的模式,在这种编程模式中最常用的函数和表达式。它强调在编程的时候用函数的方式思考问题,函数也与其他数据类型一样,处于平等地位。可以将函数作为参数传入另一个函数,也可以作为别的函数的返回值。函数式编程倾向于用一系列嵌套的函数来描述运算过程。
2017年3月13日 10:49 | # | 引用
cologler 说:
最后的例子是强行加长了过程式编程的代码的吧?
一个 then 就完了非要写成五个。
2017年3月13日 11:05 | # | 引用
yingbo 说:
Pointfree风格的getIncompleteTaskSummaries看起来很美,可是如果数据格式有可能错误就很麻烦;而且调试也很麻烦。
2017年3月13日 11:59 | # | 引用
小烈 说:
Algebra of Programming对point-free programming有深入的阐发
2017年3月13日 15:01 | # | 引用
alvin2ye 说:
恰恰相反, 函数式编程最大的好处之一就是方便调试.
2017年3月14日 09:23 | # | 引用
jone 说:
奔腾的编码思想根本停不下来,预感人工智能最终要占领地球
2017年3月14日 10:19 | # | 引用
jone 说:
回头再把柯里化的内容再看下
2017年3月14日 10:26 | # | 引用
zhlsky 说:
阮老师
你好。
您的这篇文章对我启发很大。
我个人有些疑问。
我对于pointfree的理解是:
1. 借助于柯里化把多参函数改写成单参函数
2. 在pipeline里,由于隐式的参数传递, 可以对子函数进行无参调用
这样一来就和参数无关了,切合了pointfree这个观点。
在
// 返回较大的数字
var getBiggerNumber = (a, b) => a > b ? a : b;
这里是双参。可以删除这个函数而将
var findBiggestNumber =
arr => R.reduce(getBiggerNumber, 0, arr);
改为
var findBiggestNumber =
arr => Math.max(...arr)
这样会不会好一些呢?
filterMember(member name),
这个调用可不可以改成无参调用呢?
我参考的是下面这个链接:
http://xahlee.info/comp/point-free_programing.html
再次谢谢你的博文。
2017年3月15日 13:04 | # | 引用
Jlc 说:
谢谢您的博文,谢谢您的知识分享。
2017年3月17日 11:34 | # | 引用
小菜鸟 说:
讲的很详细,很容易理解,谢谢!
2017年3月17日 20:48 | # | 引用
cshenger 说:
世界上没有什么问题是一个函数不能解决的,如果有就两个,如果还有就多个^_^
2017年3月17日 22:46 | # | 引用
catbaron 说:
这篇还是在说「怎么用」,而不是在说「为什么要用」。
最后用于比对的代码也带有强烈的目的性,过程式的代码是把函数定义放到过程中,函数式代码确是引用已经定义的函数,当然后者会易读一些。
所以我们到底为什么需要纯函数的编程?
2017年3月18日 10:26 | # | 引用
Reese Laye 说:
我一直以来都只用OOP,是函数式编程的小白。此文及《函数式编程入门教程》对我帮助很大,因为我开始了解到函数式编程的巨大优势!
2017年3月18日 18:45 | # | 引用
changsj 说:
最后的例子非常直观,直观得就像SQL
越写越像 SQL ,这些查找数据的操作
越写越像 SQL ,这些处理数据的操作
搞数据库 用SQL语言,那是不需要for循环的 ---- 真的和函数式编程好像。我喜欢
2017年3月19日 17:46 | # | 引用
juming 说:
这句话说得中肯。
2017年3月19日 19:11 | # | 引用
knightlyj 说:
我感觉例子跟面向对象或者过程差不多,只是把函数拆分得更细,方便测试,不容易出错.
2017年3月22日 21:11 | # | 引用
zxldev 说:
R.pipe(
SelectTasks,//第一数据入口
filterMember(membername),
excludeTasks(
R.pipe(
SelectTasks,//第二数据入口
filterMember(membername),
excludeTasks('Completed'),
selectFields,
sortByDueDate,
)
),
selectFields,
sortByDueDate,
switchType(
R.pipe(//第一分支出口
SelectTasks,
……
),
R.pipe(//第二分支出口
SelectTasks,
……
),
R.pipe(//第三分支出口
SelectTasks,
……
)
),
)
- -!
2017年3月23日 16:16 | # | 引用
到处抄 说:
并没有觉得这个解释了“函数式编程有什么用”,只是解答了“函数式编程怎么用”……
应该理解到本文说函数式编程提供了一种思考问题的方式,这种方式就是pointfree,通过函数的嵌套避免了循环等东西
2017年3月25日 23:52 | # | 引用
u9 说:
data.tasks.filter(i=>i.username=='Scott').sort((p,q)=>p.dueDate>q.dueDate)
还是喜欢酱紫
2017年3月29日 10:14 | # | 引用
YuanChieh 说:
十分精闢的博文!看完十分想要將函數式編程套用在日常開發中。
但我想請教老師,假設我現在是以開發網站後台的角度,我勢必會有 非Point-free的操作(DB/ IO等)與可以套用函數式編程的純資料運算的地方,請教老師能否以開發網站後台角度分享 如何將原本的過程式編程融合函數式編程開發呢?
目前對於這部分感到有些許混淆,再次感謝老師的分享
2017年4月 8日 15:48 | # | 引用
cc 说:
这个用lisp搞起来是不是更简单?
2017年4月10日 18:40 | # | 引用
iovejrj 说:
当然了:p
2017年4月13日 09:24 | # | 引用
CodingNinja 说:
Linq?我只能想到这个了
2017年4月30日 01:55 | # | 引用
qwang 说:
@阮一峰
谢谢阮老师的解释,感觉明白了很多,但是我还有一个问题。
您的用pipe连接的都是同步任务,如果是异步任务呢?是不是还是要这样
firstPromise.then(() => secondPromise).then(() => final).catch(err => handler(err));
2017年4月30日 15:00 | # | 引用
捍卫者 说:
老师,最后那个运行程序,多啦一个逗号
2017年5月 7日 14:03 | # | 引用
Elaine 说:
所以像最后一个示例中的R其实是一个static this?
2017年5月 8日 14:02 | # | 引用
燕行者 说:
同意,过程式其实这么写,代码量也不明显多:
let getIncompleteTaskSummaries = membername => {
return fetchData().then(data => {
let tasks = data.tasks;
let results = [];
for (let i = 0, len = tasks.length; i < len; i++) {
let item = tasks[i];
if (item.username === membername && !item.complete) {
let newItem = {
id: item.id,
dueDate: item.dueDate,
title: item.title,
priority: item.priority
};
results.push(newItem);
}
}
results.sort((first, second) => {
let a = first.dueDate,
b = second.dueDate;
return a < b ? -1 : a > b ? 1 : 0;
});
return results;
});
};
getIncompleteTaskSummaries('Scott').then(r => console.log(r))
2017年5月25日 11:26 | # | 引用
zhaosiwen 说:
https://jsperf.com/test-functional-programming-performance/
两种编程方式的性能比较,在较新的浏览器上,差距还是不小的,我在 Chrome 61.0.3141 / Windows 10 0.0.0下跑的,Ramda慢70%左右,如果数据量不大倒还好。
2017年7月 7日 15:53 | # | 引用
sleeper 说:
請問函式的運算能用在物件上嗎?
例:
var add2 = function () {
this.value += 2;
};
var add3 = ...
var add5 = pipe(add2, add3);
assert({value:1}.add(5).value===6);
2017年8月13日 09:12 | # | 引用
幻の上帝 说:
宁缺毋滥的玩意儿能扯成函数式……APL和shell真该哭晕在厕所。
是时候反省为啥会习惯日用语言缺少一等函数以至于造成这种错觉了。
以下正论:
去看看SKI这类纯point-free的组合子逻辑为什么没有底气替代lambda演算在PL发展过程中的历史地位,以及到底哪个更“函数式”。
还不理解的话,看看同样纯point-free的unlambda代码是如何凑出来的,以及为什么它不如带lambda抽象(“函数”)的语言实用。
2017年10月 8日 04:39 | # | 引用
topone4tvs 说:
文章很好,这点毋庸置疑~
开完下来,对pointfree有了大致的了解了~
但是后来举出的例子,让我对 过程式 和 函数式 的区别的认识变得很模糊,尤其是最后一个例子,真心没觉得有什么区别啊?难道区别就是 【一个是自己人肉实现】和【一个是调用类库来实现吗】?
2018年3月 4日 18:46 | # | 引用
砖用冰西瓜 说:
声明式编程带来的变量过多的问题怎么解决?特别是代码量很大的时候。
2018年6月 9日 16:13 | # | 引用
alex 说:
@燕行者:
这里其实不只是代码量的问题,是简单和简约的问题,你这个是更简约了不是简单了。上面那个引用的Scott Sauyet的例子我觉得没有讲的很清楚,所以读者会产生误解,这个例子里两份代码其实都是声明式写法,每一个then都是一个处理简单的一件事情的函数。第一个then是获取数据的task,第二个then是匹配username,第三个then是判断complete,第四个then是处理数据字段,第五个then是dueDate排序。这种写法可以让别的开发者很容易就理解你写的每行代码的意图,而不是读完整段代码才知道。这份代码和后者的区别是后者采用的Pointfree,把中间输出的task、result都省略了,做了一个管道,就是我们输入username,得到相应的所需数据。这个是在简单的基础上做的简约,依然很容易理解每行代码的意图。---我也是初学函数式编程,只是给后面学的人一些个人参考见解,有不对的请指出
2018年6月21日 20:01 | # | 引用
ryf-follower 说:
@zhlsky:
改成这个 R.apply(Math.max),发现了pointfree的一个小缺点,就是reduce方法必须写上0,这里有点不爽,不过也能完美解决,牛逼pointfree
var rGetLongestWordLength = R.pipe(
R.split(' '),
R.map(R.length()),
// R.reduce(R.max, 0)
R.apply(Math.max)
)
2018年8月21日 17:11 | # | 引用
Amecy 说:
fetchData().then(data =>
data.tasks
.filter(o => !o.complete)
.sort((a, b) => a.dueDate.replace(/-/g, '') - b.dueDate.replace(/-/g, ''))
)
谈一下我的理解:
通常我们把一件事分成几步,然后分步实现,需要什么写什么;函数式编程则像搭积木一样,首先要具备许多基础方法,然后把任务对应到一个个函数。
函数式编程麻烦在没有得到足够的推广,基础库有上手成本,函数式代码可能给团队成员或维护人员带来诸多不便,遇到拆分不合理或取名大神就更头疼了。
2019年1月17日 14:21 | # | 引用
travonf 说:
跟shell管道思想有点像, 一个命令/方法只负责一件简单的事情, 最终组合在一起完成复杂的事情, 易维护, 易排错, 易开发.
2019年4月24日 13:45 | # | 引用
杨立 说:
阮老师的例子里面,不能以长短来衡量并说明 函数式更有用,实际上你的每一个 then 里面的函数也是柯里化的,只不过写在了一起而已
2019年6月16日 18:16 | # | 引用
desmond 说:
最关键的问题是,如果业务复杂,你需要拆分上百个的任务的时候,过几个月再去看你自己的代码,基本上你自己都不知道什么意思了。比如某一个函数是简单的,能理解的,但是整合上百个任务的函数组合是不好理解,最大的问题是这个。我觉得是本末倒置了,失去了大局观,除非是详细的注释,把算法思想都写的很详细,否则光看代码,你完全不知道作者的思想如何。而面向过程或者面向对象的好处是大局观犹在,也就是说某一个细节可能是不清晰不清楚的,但是整体上的把控是没问题的,也就是说对于上层接口来说,我不关心底层是怎么实现的,只要接口契合就可以了。
2019年7月 5日 08:18 | # | 引用
James 说:
看了您的这篇文章,对函数式编程是有帮助的。不过用这个例子来说明其优势有点牵强,且有污名化过程式编程的嫌疑。
只有对编程理解很低的人,才会编写如例子那样的过程式编程,其效率之低无法直视。函数式编程应该有其更合适的地方,我是初次接触,继续寻找您的文章以便学习。同时也非常佩服您,希望有机会能交流。
下面是修改的过程式编程代码,感觉效率上会比函数式编程高很多,请多多指点。
```js
getIncompleteTaskSummaries = function(membername){
return fetchData()
.then(function(data){
return data.tasks.filter( (item) => {
return item.username == membername && !item.complete;
})
.sort( (first,second) => {
const a = first.dueDate;
const b = second.dueDate;
return a < b ? -1 : a > b ? 1 : 0;
});
})
.catch((err)=> console.log('错误1',err));
}
```
2020年6月12日 08:55 | # | 引用
热饭班长 说:
最后那个例子
第一个是以具体过程为粒度来解决问题
第二个是以函数为粒度来解决问题
无关代码多少,函数式编程就是将过每个过程抽象为一个函数,用函数的粒度来解决问题,而不是具体的过程实现。
2020年8月 8日 20:58 | # | 引用
Aaronlam 说:
我个人觉得过程式编程代码的例子,就是被强行以具体每个过程为粒度来编写,大家才会觉得糟糕。正常的写法我觉得应该是以最终实现的结果为导向来写的把,比如:选取username为a和complete为true,在过程是编程中就可以在一个循环中实现。
2020年10月16日 02:52 | # | 引用
flyguolai 说:
其实最像函数式编程的是变换矩阵……
多个矩阵相乘,得到一个新的矩阵
多个方法组合,得到一个新的方法
过程对外封闭,仅对输入输出负责
2021年1月 8日 15:17 | # | 引用
jerry.mei 说:
函数式编程是通过单元测试来保证程序的健壮性的,而不是debug。甚至可以说,debug都不是一种好的开发习惯,我以前太依赖debug,发现离开它复杂的算法都不会写了,程序都是调出来的,而不是写出来的。
2021年4月 5日 10:41 | # | 引用
Aaronlam 说:
感觉最后一个过程化编码的例子不是很恰当,如果实际大数据量按照任务颗粒度去进行编写,那效率恐怕只会非常低。
2021年5月15日 12:06 | # | 引用
biluo 说:
每一个then里面的功能都是单一的,这样分一下好观察和管理
2022年4月 1日 14:21 | # | 引用
严明 说:
我真是太爱阮老师了.
2023年11月 9日 13:51 | # | 引用