
一、问题的由来
URL就是网址,只要上网,就一定会用到。

一般来说,URL只能使用英文字母、阿拉伯数字和某些标点符号,不能使用其他文字和符号。比如,世界上有英文字母的网址"http://www.abc.com",但是没有希腊字母的网址"http://www.aβγ.com"(读作阿尔法-贝塔-伽玛.com)。这是因为网络标准RFC 1738做了硬性规定:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
"只有字母和数字[0-9a-zA-Z]、一些特殊符号"$-_.+!*'(),"[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。"
这意味着,如果URL中有汉字,就必须编码后使用。但是麻烦的是,RFC 1738没有规定具体的编码方法,而是交给应用程序(浏览器)自己决定。这导致"URL编码"成为了一个混乱的领域。
下面就让我们看看,"URL编码"到底有多混乱。我会依次分析四种不同的情况,在每一种情况中,浏览器的URL编码方法都不一样。把它们的差异解释清楚之后,我再说如何用Javascript找到一个统一的编码方法。
二、情况1:网址路径中包含汉字
打开IE(我用的是8.0版),输入网址"http://zh.wikipedia.org/wiki/春节"。注意,"春节"这两个字此时是网址路径的一部分。

查看HTTP请求的头信息,会发现IE实际查询的网址是"http://zh.wikipedia.org/wiki/%E6%98%A5%E8%8A%82"。也就是说,IE自动将"春节"编码成了"%E6%98%A5%E8%8A%82"。
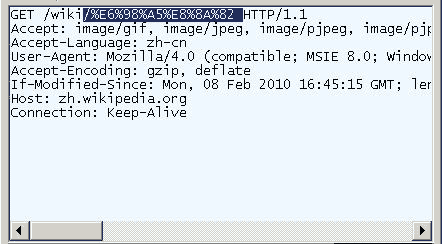
我们知道,"春"和"节"的utf-8编码分别是"E6 98 A5"和"E8 8A 82",因此,"%E6%98%A5%E8%8A%82"就是按照顺序,在每个字节前加上%而得到的。(具体的转码方法,请参考我写的《字符编码笔记》。)
在Firefox中测试,也得到了同样的结果。所以,结论1就是,网址路径的编码,用的是utf-8编码。
三、情况2:查询字符串包含汉字
在IE中输入网址"http://www.baidu.com/s?wd=春节"。注意,"春节"这两个字此时属于查询字符串,不属于网址路径,不要与情况1混淆。

查看HTTP请求的头信息,会发现IE将"春节"转化成了一个乱码。
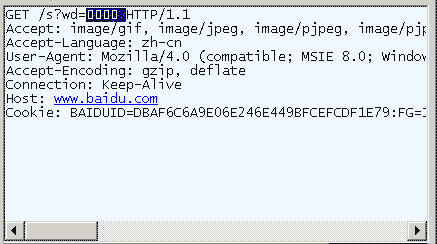
切换到十六进制方式,才能清楚地看到,"春节"被转成了"B4 BA BD DA"。
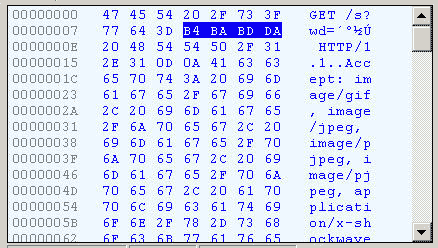
我们知道,"春"和"节"的GB2312编码(我的操作系统"Windows XP"中文版的默认编码)分别是"B4 BA"和"BD DA"。因此,IE实际上就是将查询字符串,以GB2312编码的格式发送出去。
Firefox的处理方法,略有不同。它发送的HTTP Head是"wd=%B4%BA%BD%DA"。也就是说,同样采用GB2312编码,但是在每个字节前加上了%。
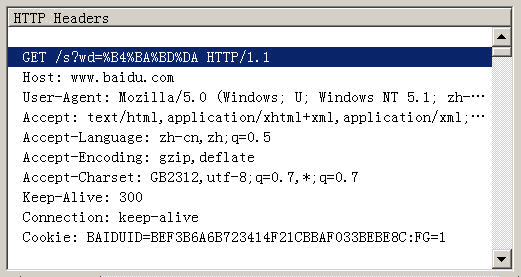
所以,结论2就是,查询字符串的编码,用的是操作系统的默认编码。
四、情况3:Get方法生成的URL包含汉字
前面说的是直接输入网址的情况,但是更常见的情况是,在已打开的网页上,直接用Get或Post方法发出HTTP请求。
根据台湾中兴大学吕瑞麟老师的试验,这时的编码方法由网页的编码决定,也就是由HTML源码中字符集的设定决定。
<meta http-equiv="Content-Type" content="text/html;charset=xxxx">
如果上面这一行最后的charset是UTF-8,则URL就以UTF-8编码;如果是GB2312,URL就以GB2312编码。
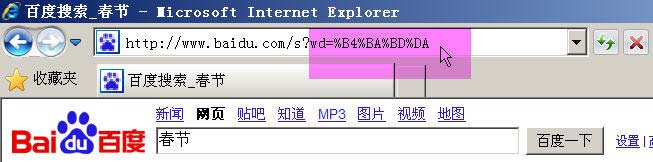
举例来说,百度是GB2312编码,Google是UTF-8编码。因此,从它们的搜索框中搜索同一个词"春节",生成的查询字符串是不一样的。
百度生成的是%B4%BA%BD%DA,这是GB2312编码。
Google生成的是%E6%98%A5%E8%8A%82,这是UTF-8编码。
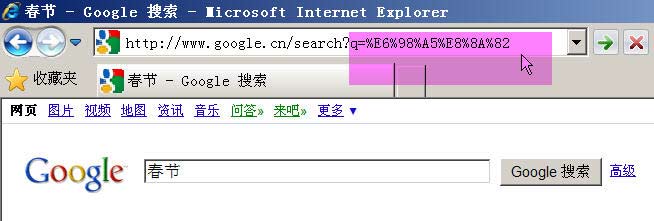
所以,结论3就是,GET和POST方法的编码,用的是网页的编码。
五、情况4:Ajax调用的URL包含汉字
前面三种情况都是由浏览器发出HTTP请求,最后一种情况则是由Javascript生成HTTP请求,也就是Ajax调用。还是根据吕瑞麟老师的文章,在这种情况下,IE和Firefox的处理方式完全不一样。
举例来说,有这样两行代码:
url = url + "?q=" +document.myform.elements[0].value; // 假定用户在表单中提交的值是"春节"这两个字
http_request.open('GET', url, true);
那么,无论网页使用什么字符集,IE传送给服务器的总是"q=%B4%BA%BD%DA",而Firefox传送给服务器的总是"q=%E6%98%A5%E8%8A%82"。也就是说,在Ajax调用中,IE总是采用GB2312编码(操作系统的默认编码),而Firefox总是采用utf-8编码。这就是我们的结论4。
六、Javascript函数:escape()
好了,到此为止,四种情况都说完了。
假定前面你都看懂了,那么此时你应该会感到很头痛。因为,实在太混乱了。不同的操作系统、不同的浏览器、不同的网页字符集,将导致完全不同的编码结果。如果程序员要把每一种结果都考虑进去,是不是太恐怖了?有没有办法,能够保证客户端只用一种编码方法向服务器发出请求?
回答是有的,就是使用Javascript先对URL编码,然后再向服务器提交,不要给浏览器插手的机会。因为Javascript的输出总是一致的,所以就保证了服务器得到的数据是格式统一的。
Javascript语言用于编码的函数,一共有三个,最古老的一个就是escape()。虽然这个函数现在已经不提倡使用了,但是由于历史原因,很多地方还在使用它,所以有必要先从它讲起。
实际上,escape()不能直接用于URL编码,它的真正作用是返回一个字符的Unicode编码值。比如"春节"的返回结果是%u6625%u8282,也就是说在Unicode字符集中,"春"是第6625个(十六进制)字符,"节"是第8282个(十六进制)字符。

它的具体规则是,除了ASCII字母、数字、标点符号"@ * _ + - . /"以外,对其他所有字符进行编码。在\u0000到\u00ff之间的符号被转成%xx的形式,其余符号被转成%uxxxx的形式。对应的解码函数是unescape()。
所以,"Hello World"的escape()编码就是"Hello%20World"。因为空格的Unicode值是20(十六进制)。

还有两个地方需要注意。
首先,无论网页的原始编码是什么,一旦被Javascript编码,就都变为unicode字符。也就是说,Javascipt函数的输入和输出,默认都是Unicode字符。这一点对下面两个函数也适用。

其次,escape()不对"+"编码。但是我们知道,网页在提交表单的时候,如果有空格,则会被转化为+字符。服务器处理数据的时候,会把+号处理成空格。所以,使用的时候要小心。
七、Javascript函数:encodeURI()
encodeURI()是Javascript中真正用来对URL编码的函数。
它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。
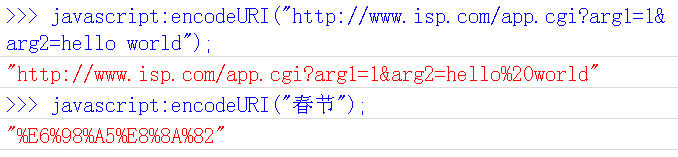
它对应的解码函数是decodeURI()。

需要注意的是,它不对单引号'编码。
八、Javascript函数:encodeURIComponent()
最后一个Javascript编码函数是encodeURIComponent()。与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。
因此,"; / ? : @ & = + $ , #",这些在encodeURI()中不被编码的符号,在encodeURIComponent()中统统会被编码。至于具体的编码方法,两者是一样。
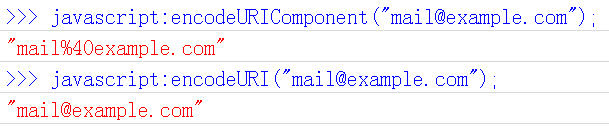
它对应的解码函数是decodeURIComponent()。
(完)

猪头四 说:
提前祝阮大哥虎年好啊。。。
2010年2月11日 19:59 | # | 引用
Jinjiang 说:
网页里的form编码其实不完全取决于网页编码,form标记中有一个accept-charset属性,在非ie浏览器种,如果将其赋值(比如accept-charset="UTF-8"),则表单会按照这个值表示的编码方式进行提交。
在ie下,我的兼容解决办法是:
form1.onsubmit=function(){
document.charset=this.getAttribute('accept-charset');
}
2010年2月11日 20:58 | # | 引用
amazing_life 说:
拜读完毕,解我心头大惑,十分感谢。
2010年2月11日 21:38 | # | 引用
Ruan YiFeng 说:
谢谢指出啊。虽然以前看到过这个属性,但是早忘了,你说了才想起来。
2010年2月12日 01:21 | # | 引用
dylanklc 说:
瀏覽器JS在解釋字符編碼時可以選擇,(不是統一按操作系統語言)瀏覽器的JS和網頁JS兩個概念.一個能調用組件,另一個不能調用組件.
參考:
[firefox] about:config 下如下選項
Network.http.accept-encoding
Network.http.accept.default
intl. accept_charsets
2010年2月12日 01:48 | # | 引用
XjAcKs 说:
长知识了!
2010年2月12日 09:04 | # | 引用
Sutra 说:
结论2的推断不严谨,你不能说某个东西和某个东西一致,它就是按照这个东西来的,小蝌蚪找妈妈呀?
2010年2月12日 09:51 | # | 引用
想~~~~ 说:
写的很不错!
2010年2月12日 10:12 | # | 引用
dulao5 说:
前面的几个情况,都和特定浏览器的特定版本、操作系统本地环境变量等情况有关系,做出结论似乎不太严谨。
2010年2月12日 10:42 | # | 引用
M 说:
补充点我的结果
情况3里,我用firefox在地址栏输入“http://www.baidu.com/s?wd=春节“访问,http header里发送的“春节”是UTF8的,然后百度就傻了,页面搜索框里显示的关键词是:鏄ヨ妭。
实际效果大概等同于 http://www.baidu.com/s?wd=%E6%98%A5%E8%8A%82,
baidu不会识别这种UTF8码的输入。
而在google,这两个地址都是可用的,等效的:
http://www.google.com/search?q=春节
http://www.google.com/search?q=%E6%98%A5%E8%8A%82
2010年2月12日 11:43 | # | 引用
M 说:
我的浏览器是Firefox 3.5.7 for ubuntu.
Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.1.7) Gecko/20100106 Ubuntu/9.10 (karmic) Firefox/3.5.7 GTB6
2010年2月12日 11:44 | # | 引用
Ruan YiFeng 说:
这属于情况2,不属于情况3。
接受你的批评,我的样本确实少了点。不过,最常见的情况应该都讨论到了。
2010年2月12日 13:26 | # | 引用
est 说:
阮兄noob了。。。这个是网页自己指定的charset,指定gb2312什么就提交gb2312,指定utf8就提交utf8
2010年2月12日 13:36 | # | 引用
Ruan YiFeng 说:
To est:
你说的是情况3。
情况1、情况2和情况4都与网页本身指定的charset无关。尤其是前两种情况,这时浏览器还不知道网页本身的编码呢。
2010年2月12日 13:52 | # | 引用
Jinjiang 说:
不客气~
我也是最近写了一个可以登录各种邮箱和社区的表单时,为了应付各个站点要求不同编码方式的表单提交,才注意到这个属性的,今天看到您在此讨论编码问题,所以拿出来分享一下~ 呵呵
2010年2月12日 16:16 | # | 引用
lhb2002200000 说:
提前祝阮大哥虎年好啊。。。
2010年2月12日 16:31 | # | 引用
janlay 说:
情况1和2本质上是一样的,在web server内部会把1转换成2的形式。其实使用何种编码,都是取决与如何“约定”————服务器对客户端提交的数据使用何种编码有约定,客户端只有按约定的编码发送信息,才会被正确decode.
2010年2月12日 17:21 | # | 引用
BruceGAO 说:
解决了我一直以来的困惑
2010年2月12日 17:50 | # | 引用
234 说:
太好了,编码用于争取夺走的权利
2010年2月12日 18:36 | # | 引用
est 说:
HTTP头也可以直接指定charset的。用抓包软件看看 Content-Type: text/html; charset=utf-8
如果HTTP头也没有指定,那就和浏览器设置有关。如果浏览器也没有设置,那就和当前进程系统设置(codepage)有关。如果和当前进程无关,那么就是操作系统默认编码了。编码和URL并没有绝对关系。
2010年2月13日 14:14 | # | 引用
ok s 说:
这样的文章,读起来舒服!!!
2010年2月13日 14:16 | # | 引用
Tony 说:
新年快乐!
2010年2月13日 23:13 | # | 引用
gallen 说:
情况一不是很明白
情况二的话,在IE中用wireshark抓包,貌似变成了“\264\272\275\332\”并非传说中的URL“%B4%BA%BD%DA”虽然只是表示有点不一样,可就是不明白为啥没有“%”这个百分号了呢?
不吝赐教~
2010年5月21日 13:49 | # | 引用
cst 说:
结论二的推论是有问题的
用一个utf-8的网站反而更有说服力
2010年7月 9日 10:32 | # | 引用
ahui 说:
确实挺乱的,也许将来会出一个统一的标准吧!
2010年10月10日 10:58 | # | 引用
沐沐 说:
原创否?
2010年11月16日 15:58 | # | 引用
weixing 说:
我是菜鸟,想请教一下你前面看他们的编码工具是什么啊?怎么查看的啊?
2010年11月21日 23:35 | # | 引用
江哥 说:
有一点问题:
URL编码是否正确,跟选用的服务器有关。
你可以尝试http://www.google.com.hk/search?hl=zh-CN&q=%E6%98%A5%E8%8A%82跟http://www.google.com.hk/search?hl=zh-CN&q=%B4%BA%BD%DA,均可以正常解析。
显然,Google的服务器内置了编码转换。
对目前最流行的Apache服务器来说,URL的编码跟页面的编码保持一致。你所说的第1种情况跟第2种情况,不过是由于wiki采用UTF-8,而Baidu采用GBK编码的原因。
2010年12月12日 15:08 | # | 引用
ch 说:
请交一下搜索繁体字的时候浏览器是真么编码的?
比如搜索“商業網站”, 百度的搜索引擎会出现%C9%CC%98I%BEW%D5%BE这样的编码。 开头的“%C9%CC就是“商”,结尾的“%D5%BE”就是“站”,而中间的两个繁体字URL编码成了“%98I%BEW”。 一般%号后面都是两个字母,繁体怎么会有三个字母呢?
2010年12月17日 14:57 | # | 引用
大名 说:
还是不懂, 那你用不同的编码,服务器是什么解析的
2011年4月13日 22:17 | # | 引用
Qujer 说:
初学PHP,感觉很受用!
2011年8月21日 20:59 | # | 引用
alswl 说:
感谢阮老师,解决了一个大问题
2011年9月19日 16:50 | # | 引用
清晨的来客 说:
对于结论2,我觉得有点问题,用谷歌www.google.com.hk查询时,URL的编码为UTF-8,我觉得是网站使用的编码有关的吧。
2011年9月26日 13:22 | # | 引用
sking7 说:
凭某个测试结果总结出来的规则是不严谨的。。。
仅我知道的,在tomcat里,结论3未必是正确的,get的编码是否和网页编码一致取决于tomcat是否设置了某个属性
结论3就是,GET和POST方法的编码,用的是网页的编码。
2011年10月 9日 11:10 | # | 引用
zz 说:
好文章啊 很详细!
2011年11月 4日 10:07 | # | 引用
飞龙 说:
不管结论如何,讨论问题的思路还是很清楚的。
愿意研究,依次尝试下来,都会有写收获
2011年11月 5日 15:22 | # | 引用
grick 说:
这个问题或许没那么简单,因为服务器端比如 IIS, APACHE 还会对 URL 中的字符进行解码处理。头疼啊,为什么这么棘手的问题很少有人深入讨论? 编码问题绝对是个毒瘤。
2011年11月20日 21:30 | # | 引用
xin 说:
总结的很好,很喜欢。
2012年2月21日 14:38 | # | 引用
wang20061040 说:
url编码的确是个头痛的事
2012年4月 5日 11:25 | # | 引用
yutianhuo 说:
哥们,你的文章太值得读了,拜谢!
2012年5月22日 14:41 | # | 引用
chorles 说:
我想问一下下面这个地址中波浪线“~”在URL中起什么作用啊?
http://www.cs.tut.fi/~jkorpela/html/strict.html
p.s.请邮件告知,多谢!
chorles#sohu.com #->@
2012年8月13日 01:25 | # | 引用
Ltn 说:
请问下怎么把URL转化为UR这类型的?
请问有工具直接转换吗?
2012年9月 5日 13:53 | # | 引用
广告位不招租 说:
干货,赞!
使用encodeURI输出的是UTF8编码格式的,如果是通过get方式发出请求,但请求地址是第三方GB2312的页面,可能会出现乱码情况,该如何处理?
2012年9月28日 13:22 | # | 引用
00_悦 说:
写得很详细,受教了
2013年4月 8日 10:55 | # | 引用
qianguozheng 说:
关于将网页提交表单时将 空格转换为+,在哪里有比较官方的声明呢?
2013年7月17日 09:38 | # | 引用
出来忘吃药了 说:
捐款完毕2元(汗颜)!真正帮助了我解决了实际问题。如果不捐,过去因这个问题而痛苦挣扎的我,会恨自己。
2013年8月24日 17:41 | # | 引用
苹果 说:
我对情况2做了练习,在地址栏里直接输入:“http://www.baidu.com/s?wd=春节”。结果在firebug中看到的是:
GET /s?wd=%E6%98%A5%E8%8A%82 HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:24.0) Gecko/20100101 Firefox/24.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Cookie: BAIDUID=414B5AFB67FF1218D91F5FDBF032143E:FG=1
Connection: keep-alive
“春节”两个汉字被用UTF-8编码了,而不是GB2312
请问:是我做的过程有问题,还是Firefox升级,造成的?到底该怎么对待地址重写中汉字的编码?
2013年10月10日 19:10 | # | 引用
林晨 说:
从内容和表达都很到位。 alipay不支持pc捐款了,阮老师给个二维码吧
2014年5月15日 12:06 | # | 引用
FM 说:
写的详实,很不错
2014年5月15日 17:44 | # | 引用
hello 说:
"只有字母和数字[0-9a-zA-Z]、一些特殊符号"$-_.+!*'(),"[不包括双引号]、以及某些保留字,才可以不经过编码直接用于URL。"
这句话中特殊符号那里是不是有问题,难道%,/,=,这几个符号都不能直接用于url?这些都是常见的啊
2014年11月24日 19:41 | # | 引用
junfx 说:
我想在C中进行url编码, 解码, 搜到了这里.
根据自己的观察, 结合你文章的几个结论, 发现 *可能* 的原则是:
对于中文, 文本框的编码是GBK/Unicode/xxx, 那么URL编码用的就是GBK/Unicode/xxx.
这里的文本框可以是地址栏, 表单输入, 文件, ...
未验证.
2014年12月 2日 13:24 | # | 引用
Twistack 说:
谢谢,您的很多文章都帮我大忙了:)
2015年9月16日 16:32 | # | 引用
微笑 说:
chrome中情况2用的是utf-8,请阮大牛确认
2015年12月11日 11:02 | # | 引用
一树繁花 说:
解决了我的问题,非常感谢
2016年5月18日 12:08 | # | 引用
zhangolve 说:
看了您的这篇文章还有那篇讲编码的,很受用,原来碰到的问题解决了
2016年7月 7日 07:43 | # | 引用
李思明 说:
您好,我现在通过字符串解析的办法提取html中所有url,然后replace成编码后的形式,那么浏览器打开后其实又会对‘%’符号进行一次编码,导致html无法正常运行,请问这种情况跟您说的用js对url编码后向服务器提交有什么区别吗?
2016年8月25日 15:36 | # | 引用
Johnson 说:
阮大大,您的博客真是太好了.今天又帮了我一个大忙!!!
2016年9月20日 16:27 | # | 引用
weniqng 说:
是的,现在测试IE-Edge版,用的都是utf-8编码
2017年5月16日 14:41 | # | 引用
rzet 说:
对于encodeURI 和 encodeURIComponent 区别是什么还是说的不清楚?
encodeURI:【它着眼于对整个URL进行编码,因此除了常见的符号以外,对其他一些在网址中有特殊含义的符号"; / ? : @ & = + $ , #",也不进行编码。编码后,它输出符号的utf-8形式,并且在每个字节前加上%。】
encodeURIComponent【 与encodeURI()的区别是,它用于对URL的组成部分进行个别编码,而不用于对整个URL进行编码。】
什么是着眼于整个URL?如何理解?
2018年4月10日 13:25 | # | 引用
Lusian 说:
最近也在研究编码这一块,看完这篇文章之后思路清晰了很多,在此表示感谢。但是还有一个疑惑没能解决,如果情况有那么多种,难道就没有一个固定字段标明准确的编码格式的吗?
2019年1月28日 17:39 | # | 引用
不曾潇洒 说:
@rzet:
我的理解是encodeURI可以直接对整个url进行编码
encodeURIComponent用于对参数部分编码
因为encodeURIComponent会对 / ? :编码,如果用于完整的URL编码就会把http://xx?sss的不该编码的字符编码了
2019年6月21日 18:00 | # | 引用
byqbai 说:
2010 年3月23日,谷歌中国声明因“遭受中国黑客攻击”和“网络审查”决定退出中国市场。 Google公司将原有谷歌中国的两域名(google.cn和g.cn)中的网页、图片和资讯(后更名为“新闻”)等搜索服务重定向至Google香港(google.com.hk)。
现在已经过去十年了
2020年1月 9日 16:46 | # | 引用
wammss 说:
@rzet:
假如现在需要在http://www.baidu.com/s后面拼接查询字符串?wd=你好&春节 ,如果你用encodeURI()对拼接后的url编码,那么特殊字符&不会被编码,服务器拿到url后将不能正确解析出查询字符串,这个时候你应该对查询字符串部分单独使用encodeURIComponent()进行编码,然后再拼接至url后面
2020年3月17日 12:07 | # | 引用
tfans 说:
"...Only alphanumerics [0-9a-zA-Z], the special characters "$-_.+!*'()," [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL."
- ed是啥意思?
2021年2月24日 11:45 | # | 引用
2022 说:
年复一年又一轮,虎年安康
2022年1月24日 13:23 | # | 引用
海豚 说:
看了您的文章,豁然开朗!解决了我做的集成搜索框,对自己很有帮助!
2022年2月11日 10:37 | # | 引用