
(不好意思,这个系列中断了近两周,我会尽快在这几天,把后面几篇写完。)
上一次,我介绍了Hacker News的排名算法。它的特点是用户只能投赞成票,但是很多网站还允许用户投反对票。就是说,除了好评以外,你还可以给某篇文章差评。
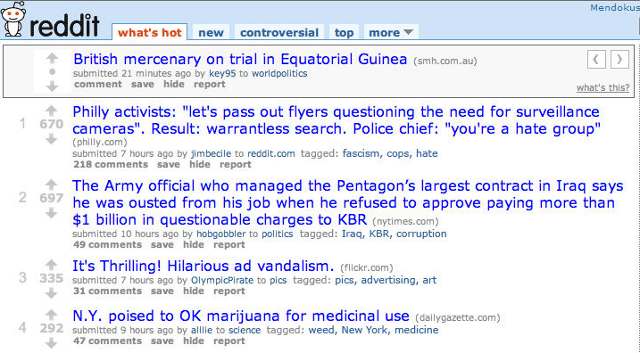
Reddit是美国最大的网上社区,它的每个帖子前面都有向上和向下的箭头,分别表示"赞成"和"反对"。用户点击进行投票,Reddit根据投票结果,计算出最新的"热点文章排行榜"。
怎样才能将赞成票和反对票结合起来,计算出一段时间内最受欢迎的文章呢?如果文章A有100张赞成票、5张反对票,文章B有1000张赞成票、950张反对票,谁应该排在前面呢?
Reddit的程序是开源的,使用Python语言编写。排名算法的代码大致如下:
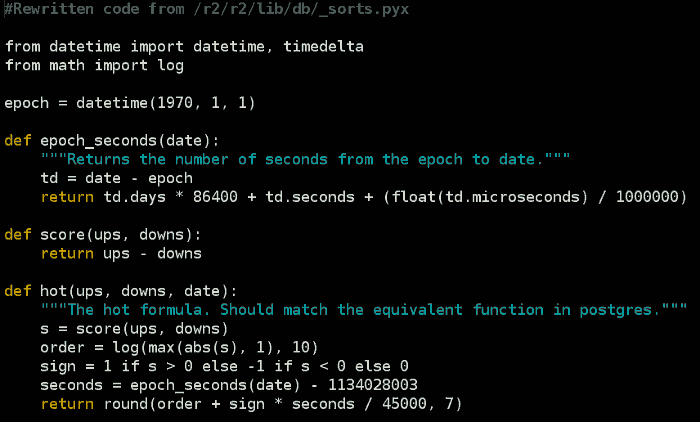
这段代码考虑了这样几个因素:
(1)帖子的新旧程度t
t = 发贴时间 - 2005年12月8日7:46:43
t的单位为秒,用unix时间戳计算。不难看出,一旦帖子发表,t就是固定值,不会随时间改变,而且帖子越新,t值越大。至于2005年12月8日,应该是Reddit成立的时间。
(2)赞成票与反对票的差x
x = 赞成票 - 反对票
(3)投票方向y
y是一个符号变量,表示对文章的总体看法。如果赞成票居多,y就是+1;如果反对票居多,y就是-1;如果赞成票和反对票相等,y就是0。
(4)帖子的受肯定(否定)的程度z
z表示赞成票与反对票之间差额的绝对值。如果对某个帖子的评价,越是一边倒,z就越大。如果赞成票等于反对票,z就等于1。
结合以上几个变量,Reddit的最终得分计算公式如下:
这个公式可以分成两个部分来讨论:
(一)
这个部分表示,赞成票与反对票的差额z越大,得分越高。
需要注意的是,这里用的是以10为底的对数,意味着z=10可以得到1分,z=100可以得到2分。也就是说,前10个投票人与后90个投票人(乃至再后面900个投票人)的权重是一样的,即如果一个帖子特别受到欢迎,那么越到后面投赞成票,对得分越不会产生影响。
当赞成票等于反对票,z=1,因此这个部分等于0,也就是不产生得分。
(二)
这个部分表示,t越大,得分越高,即新帖子的得分会高于老帖子。它起到自动将老帖子的排名往下拉的作用。
分母的45000秒,等于12.5个小时,也就是说,后一天的帖子会比前一天的帖子多得2分。结合前一部分,可以得到结论,如果前一天的帖子在第二天还想保持原先的排名,在这一天里面,它的z值必须增加100倍(净赞成票增加100倍)。
y的作用是产生加分或减分。当赞成票超过反对票时,这一部分为正,起到加分作用;当赞成票少于反对票时,这一部分为负,起到减分作用;当两者相等,这一部分为0。这就保证了得到大量净赞成票的文章,会排在前列;赞成票与反对票接近或相等的文章,会排在后面;得到净反对票的文章,会排在最后(因为得分是负值)。
(三)
这种算法的一个问题是,对于那些有争议的文章(赞成票和反对票非常接近),它们不可能排到前列。假定同一时间有两个帖子发表,文章A有1张赞成票(发帖人投的)、0张反对票,文章B有1000张赞成票、1000张反对票,那么A的排名会高于B,这显然不合理。
结论就是,Reddit的排名,基本上由发帖时间决定,超级受欢迎的文章会排在最前面,一般性受欢迎的文章、有争议的文章都不会很靠前。这决定了Reddit是一个符合大众口味的社区,不是一个很激进、可以展示少数派想法的地方。
[参考资料]
* How Reddit ranking algorithms work
(完)

张刚 说:
发表这类专业化太强的内容,确实很耗费时间,期待后面的内容
2012年3月 7日 16:40 | # | 引用
令狐虫 说:
文中对z的解释跟代码不一致啊。代码中是 max(abs(s), 1), 也就是说只看赞成票和反对票的差距,差距越大值越大。并没有区别对待赞成票还是反对票的意思。
2012年3月 7日 17:32 | # | 引用
邵伟超 说:
对z的解释确实跟代码不一致啊,求解释
2012年3月 7日 17:48 | # | 引用
阮一峰 说:
啊,我看代码不仔细,这个地方没注意到。
这篇文章要大幅度改写了……
2012年3月 7日 18:26 | # | 引用
阮一峰 说:
改过z了,现在与代码一致了。
2012年3月 7日 18:59 | # | 引用
bobo 说:
分析的不错,感觉算法写的中规中矩。
2012年3月 7日 19:22 | # | 引用
周琪 说:
这几天正想琢磨,结果就看到了,真是不错。
2012年3月 7日 22:46 | # | 引用
Hank 说:
不知道有沒有中文網站可以和Reddit相提並論
2012年3月 7日 22:49 | # | 引用
必填 说:
这个绝对值的设计好像没什么用啊,反对票远大于赞成票的文章一下子就被sign*seconds/45000给踢到后面去了,很难靠按照对数增长的order拉回来。
2012年3月 8日 01:04 | # | 引用
erben 说:
结论不太对。文章讨论的都只是hot函数,原链接里还有个controversy函数。最后不一定只是用hot排序的。
2012年3月 8日 03:07 | # | 引用
刘永新 说:
这个公式基本决定了:"Reddit的排名,基本上由发帖时间决定"!
2012年3月 8日 09:48 | # | 引用
duyt1001 说:
我看了一下github上帝reddit源代码,发现他其实除了hot以外还有计算争议值:
cpdef double controversy(long ups, long downs):
"""The controversy sort."""
return float(ups + downs) / max(abs(score(ups, downs)), 1)
在queries.py中新票和老票都是同时计入了hot, top 和controversy的值。虽然没有仔细看,但是应该是如果1000赞成+1000反对还是会比1赞成+0反对要排前的。
2012年3月 8日 10:10 | # | 引用
Johnny 说:
大虾,能知道编辑器名字吗,code看起来很舒服
2012年3月 8日 11:47 | # | 引用
微卓 说:
都是人才阿。。。
2012年3月 8日 14:31 | # | 引用
Ranger 说:
最后的分析有道理
2012年3月 8日 15:34 | # | 引用
61 说:
因为他有y来控制方向呀。。所以对z不区分应该没什么问题的
2012年3月 8日 17:02 | # | 引用
Answer Johnny 说:
代码是图片来的,可以点开,点开来看就知道了。
2012年3月14日 13:07 | # | 引用
phplaber 说:
2012年3月16日 10:33 | # | 引用
sophia 说:
如果反对票超过赞成票,且超过越多,Z也越大 这个怎么解释啊?
2012年3月16日 10:56 | # | 引用
cfanvip 说:
博主的php编辑器是什么软件呀 好酷呀 英文字体也特别养眼 希望告知软件名称和字体哦 支持下~
2012年3月21日 16:30 | # | 引用
alexwhu 说:
同问!!
order = log(max(abs(ups - downs), 1), 10) 这部分对结果影响不小吧
2012年3月23日 17:42 | # | 引用
alexwhu 说:
对于downs 比 ups 多的items, 主要靠 y*t / 45000 来调节了。
为什么不来更狠点的?
order = y * log(max(abs(ups - downs), 1), 10) + y*t / 45000
如果这么狠的话,那么downs比ups多的items,估计就永无天日能被用户看到了,
其实有时候,downs比ups多的items,也是很有意思的item,至少能够吸引用户眼球,
所以,使用log(max(abs(ups - downs), 1), 10),来给予他们一些能够“见天日”的机会,之余到底能否排上名“见到天日”,就看 y*t 了,如果是很旧的items,那么真的无法排上名了,如果是很新的items,虽然反对票很多,但是因为item出来新,还是可以给用户看看的...
2012年3月23日 17:56 | # | 引用
Quady 说:
我认为这算法设计的思路还是挺好的,新旧、方向、拉伸力度,值得学习。
文章很好的解释了其中的思路!
2012年3月31日 16:35 | # | 引用
城主 说:
应该可以再加上一项 k*(赞成数+反对数),投票总数也是一项指标呢
2012年4月 1日 10:30 | # | 引用
scys 说:
那个 yt,还以为是 y的 t次方呢,看了半天没看懂,后来看了结尾给的链接文章,才明白原来是 y 乘 t, 呵呵!
2012年11月 7日 18:40 | # | 引用
lvv2.com 说:
用php搭建的,算法与reddit一样。欢迎访问 lvv2.com 如果您访问不到的话,那就是在墙外了。这里没有言论审查。。其中,有争论的 选项算法是
$s = $ups+$downs;
$argue = $ups>$downs?$downs/$ups:$ups/$downs;
$order = log10(max($s,1))*$argue;
$seconds = $date - strtotime('2011-05-10');
return round($order + $seconds/45000,7);
欢迎各位提建议补充,lvv2.com
2012年12月22日 22:07 | # | 引用
carusd 说:
从公式上看,两篇先后发布的文章,如果赞成和反对票一直是0,那么他们的分值都一样是0。这样一来新发布的文章不就一直排不到前面,二来两篇这样的文章也不知道该怎么排序。这样真的没问题吗?
2013年9月29日 17:10 | # | 引用
林夕 说:
reddit还有一个排名【上升】是根据上升速度来排的,谁知道这个是怎么实现的吗?
2014年2月26日 20:46 | # | 引用
林夕 说:
reddit的算法有一些漏洞,比如假设两篇文章,相距5秒发布。每一个都收到两个负面评价,seconds对于新文章值更大一些,但是因为sign为负值,新的文章评分反而比旧的文章低。详见http://blog.jobbole.com/53406/
2014年2月27日 10:07 | # | 引用
张云峰 说:
您好看了你的关于reddit的文章,请问是否可以邀请您一起做基于这个系统的一个知识社交网站
我QQ65384403 谢谢 请加我
2015年2月17日 10:26 | # | 引用
jackie 说:
嗨, 请问这个排序算法问什么不用机器学习来做呢?
用逻辑回归, 预估一个帖子是否被用户查看的概率, 用这个概率来排序.
2015年9月30日 13:49 | # | 引用
杨德宇 说:
公式都消失了。。有没有办法还原啊。麻烦了
2017年3月15日 23:05 | # | 引用
van 说:
“前10个投票人与后90个投票人(乃至再后面900个投票人)的权重是一样的”,应该是不一样的吧?
2017年8月25日 15:39 | # | 引用
Darry 说:
刚看完阮老师的排名算法有分析Reddit这个论坛的机制,然后就看到这个论坛的科技新闻——深度学习的deepfakes;阮老师6年前的文章挑选的还真都是很典型的案例,Reddit这个论坛还这么火呢
2018年1月31日 01:14 | # | 引用
zahi 说:
阮老师您好,最近在研究相关算法,您的文章写的非常好,但由于大部分图片无法显示,理解起来很困难,可否更新一下对应的图片
2019年2月16日 15:05 | # | 引用
qqq 说:
翻墙之后图片都能正常显示,图片上传的服务器被墙了?
2020年5月 5日 12:01 | # | 引用