
学习编程的时候,经常会看到stack这个词,它的中文名字叫做"栈"。
理解这个概念,对于理解程序的运行至关重要。容易混淆的是,这个词其实有三种含义,适用于不同的场合,必须加以区分。
含义一:数据结构
stack的第一种含义是一组数据的存放方式,特点为LIFO,即后进先出(Last in, first out)。
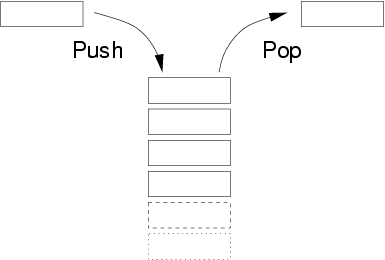
在这种数据结构中,数据像积木那样一层层堆起来,后面加入的数据就放在最上层。使用的时候,最上层的数据第一个被用掉,这就叫做"后进先出"。
与这种结构配套的,是一些特定的方法,主要为下面这些。
- push:在最顶层加入数据。
- pop:返回并移除最顶层的数据。
- top:返回最顶层数据的值,但不移除它。
- isempty:返回一个布尔值,表示当前stack是否为空栈。
含义二:代码运行方式
stack的第二种含义是"调用栈"(call stack),表示函数或子例程像堆积木一样存放,以实现层层调用。
下面以一段Java代码为例(来源)。
class Student{ int age; String name; public Student(int Age, String Name) { this.age = Age; setName(Name); } public void setName(String Name) { this.name = Name; } } public class Main{ public static void main(String[] args) { Student s; s = new Student(23,"Jonh"); } }
上面这段代码运行的时候,首先调用main方法,里面需要生成一个Student的实例,于是又调用Student构造函数。在构造函数中,又调用到setName方法。
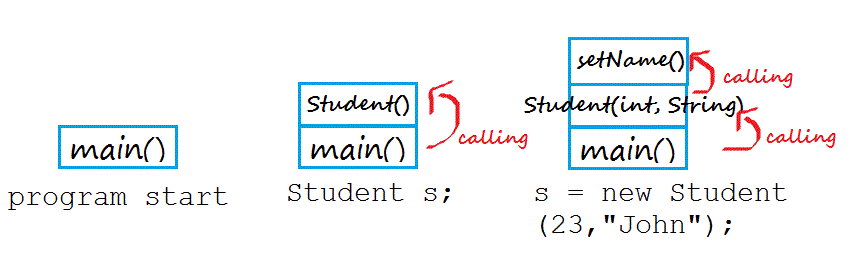
这三次调用像积木一样堆起来,就叫做"调用栈"。程序运行的时候,总是先完成最上层的调用,然后将它的值返回到下一层调用,直至完成整个调用栈,返回最后的结果。
含义三:内存区域
stack的第三种含义是存放数据的一种内存区域。程序运行的时候,需要内存空间存放数据。一般来说,系统会划分出两种不同的内存空间:一种叫做stack(栈),另一种叫做heap(堆)。

它们的主要区别是:stack是有结构的,每个区块按照一定次序存放,可以明确知道每个区块的大小;heap是没有结构的,数据可以任意存放。因此,stack的寻址速度要快于heap。

其他的区别还有,一般来说,每个线程分配一个stack,每个进程分配一个heap,也就是说,stack是线程独占的,heap是线程共用的。此外,stack创建的时候,大小是确定的,数据超过这个大小,就发生stack overflow错误,而heap的大小是不确定的,需要的话可以不断增加。
根据上面这些区别,数据存放的规则是:只要是局部的、占用空间确定的数据,一般都存放在stack里面,否则就放在heap里面。请看下面这段代码(来源)。
public void Method1() { int i=4; int y=2; class1 cls1 = new class1(); }
上面代码的Method1方法,共包含了三个变量:i, y 和 cls1。其中,i和y的值是整数,内存占用空间是确定的,而且是局部变量,只用在Method1区块之内,不会用于区块之外。cls1也是局部变量,但是类型为指针变量,指向一个对象的实例。指针变量占用的大小是确定的,但是对象实例以目前的信息无法确知所占用的内存空间大小。
这三个变量和一个对象实例在内存中的存放方式如下。

从上图可以看到,i、y和cls1都存放在stack,因为它们占用内存空间都是确定的,而且本身也属于局部变量。但是,cls1指向的对象实例存放在heap,因为它的大小不确定。作为一条规则可以记住,所有的对象都存放在heap。
接下来的问题是,当Method1方法运行结束,会发生什么事?
回答是整个stack被清空,i、y和cls1这三个变量消失,因为它们是局部变量,区块一旦运行结束,就没必要再存在了。而heap之中的那个对象实例继续存在,直到系统的垃圾清理机制(garbage collector)将这块内存回收。因此,一般来说,内存泄漏都发生在heap,即某些内存空间不再被使用了,却因为种种原因,没有被系统回收。
(完)

才不是永超呢 说:
栈是线程的。堆是进程的。涨姿势了。
2013年11月29日 11:39 | # | 引用
resty 说:
stack的读取速度要比heap快的理论是怎么想出来的......
2013年11月29日 11:54 | # | 引用
Joey 说:
赞,简洁易懂
2013年11月29日 12:35 | # | 引用
Henry 说:
所有语言通用还是只对.Net,因为我看到你引用的文章是正对.Net的,
2013年11月29日 12:40 | # | 引用
yk 说:
2013年11月29日 12:43 | # | 引用
damon 说:
第一种语义是基础,第三种语义是第一种的实现,第二种语义是第三种语义的表现
2013年11月29日 12:52 | # | 引用
阮一峰 说:
@resty, @yk:
谢谢指出,我已经做了修改。
2013年11月29日 13:14 | # | 引用
阿伦 说:
通俗易懂,写得真好。
2013年11月29日 13:21 | # | 引用
Chao 说:
建议您去读一下CSAPP 和 操作系统相关的书, 您第二个和第三个解释错误太多了
2013年11月29日 13:39 | # | 引用
StanleyZ 说:
后两种算一回事, 函数调用和栈上数据都是使用同一块区域, 同样的进出方式. 非要从逻辑上区分会误导人吧.
2013年11月29日 13:47 | # | 引用
Jeff 说:
第二跟第三是同一个区域吧
2013年11月29日 13:48 | # | 引用
Y 说:
配图是用什么画出来的
2013年11月29日 13:50 | # | 引用
Jex 说:
我觉得这个文章显然是不严谨的,有点误导性。
第一条是基本概念的解释。
后面两个都是举例对Stack这种结构的一种应用。
文中说“因此,stack的寻址速度要快于heap”的理由显然是模糊不清的。如果只谈“寻址速度”(这术语不好说),stack上的数据的地址通常在编译时已经确定成一个相对stack base pointer(%ebp)的偏移,而heap中的地址则通常要运行时分配才确定。如果谈访问速度,stack比heap更快的原因则主要取决于CPU Cache和操作系统的实现。
但我的理解两者都并不是因为heap中的数据是无结构的。更何况heap中的数据无结构这种说法也不好理解啊,什么叫“无结构”呢?
2013年11月29日 16:37 | # | 引用
小白 说:
1是普通程序员对栈的应用,
2,3是CPU对栈的应用吧.
2013年11月29日 16:54 | # | 引用
ljqx 说:
“作为一条规则可以记住,所有的对象都存放在heap。”这句对C++里的局部变量对象(非指针)适用吗?
2013年11月29日 21:27 | # | 引用
YangZX 说:
不得不说这篇文章解释得不太到位。
“第二种含义”和“第三种含义”实际上只是 第一种含义(也是唯一的含义)的一个应用。并且实际上这两个是同一个栈。
阮老师有时间可以读读CSAPP
2013年11月30日 09:30 | # | 引用
JayXon 说:
Stack只有一种含义就是第一种,后面俩都是利用这种数据结构做的一些东西而已
2013年11月30日 10:09 | # | 引用
张冲 说:
我能问一下,上边的图是用什么软件画出来的吗?
喜欢画图去表达想法,找不到合适的工具。
2013年11月30日 10:30 | # | 引用
三心二意 说:
Mockups
2013年11月30日 13:51 | # | 引用
BryantGui 说:
讲的很有道理,有个小问题,malloc调用heap分配实现的,而不是heap分配调用malloc。
2013年11月30日 21:36 | # | 引用
哥墨迹 说:
脱离了Java的范畴,有些概念是否不太适用?
2013年11月30日 23:56 | # | 引用
zechuan 说:
讲得好清楚啊,涨姿势!
2013年12月 1日 14:33 | # | 引用
烤全羊 说:
大家都发现了,这三个对Stack的解释是一个意思,没有本质区别
2013年12月 1日 20:26 | # | 引用
I小志T 说:
楼主好人,以前有些模糊的概念,清楚多了!
2013年12月 2日 00:11 | # | 引用
kmxz 说:
下次讲讲 heap 的几个含义?
2013年12月 2日 09:21 | # | 引用
tossking 说:
总觉得这篇文章有的地方不对劲
写的不太对
2013年12月 2日 10:15 | # | 引用
Gamer 说:
“建议你去读《XXX》书”,这种废话还用你来说?你要是觉得原文由错的话请直接指出来,让大家判断一下。
2013年12月 4日 12:56 | # | 引用
muwb 说:
含义三对理解jvm很有帮助哈。每个线程都有独立的TLAB,线程执行是用到的对象通过ref链接到heap中实例的地址,估计是这样的
2013年12月 4日 18:43 | # | 引用
宇飞 说:
第二个和第三个是同一个内存区, 不仅包含了local variable, 也有函数返回地址, 正是因为如此buffer overflow 的攻击才有可能发生。如此分开解释会造成误导。
2013年12月 5日 15:07 | # | 引用
bombless 说:
总结的不错。
2013年12月 8日 11:17 | # | 引用
Biwood 说:
终于有点能看懂的了
2013年12月 8日 19:50 | # | 引用
春风化雨 说:
这个问题以前也想了几次,不过没有你想的深入。
2013年12月 9日 23:49 | # | 引用
张利龙 说:
受益匪浅!谢谢分享
2013年12月10日 09:05 | # | 引用
scmroad 说:
请问您这篇文章里面的图片是用什么画的?还有字体。谢谢
2013年12月11日 08:18 | # | 引用
weixue 说:
堆和栈在程序运行的时候应该都是处于相同的一块内存区域(从程序的整体角度来看),代码段、数据段、栈、堆,所以说存取速度应该是一样的。
我觉得从cpu和cache上来看他们都是内存,应该都是没什么差别的,但是申请堆上的空间涉及到操作系统中用户态和核心态之间的切换之类的,所以主要的差别可能就是在操作系统层面上的吧。
2013年12月13日 10:55 | # | 引用
xfxlch 说:
jvm里面说一个线程对应一个虚拟机栈,而堆是针对的整个虚拟机的运行过程中的
2013年12月15日 17:30 | # | 引用
小谈 说:
阮老师好像不是计算机专业的,但是对计算机知识的钻研比较深入,而且很专业,涉猎广泛,这种学习和钻研的精神值得我们学习啊!!
2013年12月16日 14:09 | # | 引用
马化腾 说:
说的不对
2013年12月17日 09:50 | # | 引用
李彦宏 说:
楼上的,这么巧?
2013年12月17日 18:22 | # | 引用
fyp 说:
感觉评论很精彩,不过阮老师讲的也很透彻,期待更好的文章。
2013年12月18日 17:09 | # | 引用
BinaryHB 说:
函数(C++)和方法(Java)什么的叫法,不区分开。Java里没有指针。这些东西真的很伤我这样的初学者的。。
2013年12月22日 15:58 | # | 引用
KG 说:
很精彩!以前有时候偶尔看看堆和栈的区别,但是过段时间又忘了。阮老师这篇文章很浅显易懂,这里的评论都很精彩,大家的学习兴趣很大!
2013年12月27日 15:42 | # | 引用
luobenxlnslb 说:
作者表达能力很强,佩服!
2014年1月 3日 17:13 | # | 引用
马云 说:
正在看linux内核,希望阮老师写点汇编和内核的东西。
2014年1月 3日 17:50 | # | 引用
Hao 说:
应该说的是分配内存的速度吧。
2014年1月 4日 07:35 | # | 引用
Gin 说:
pop:返回并移除最顶层的数据,您说的是java里的吗?c++的是移除最顶层的数据,但是不返回。
2014年1月 4日 18:43 | # | 引用
yfractal 说:
stack 感觉翻译成柴火堆(或者做下可视化)什么的,就很好理解。再比如比较坑的是权重,就是weight。更坑的是,正则表达。。。
2014年1月 6日 07:20 | # | 引用
Fred 说:
通常我会这么理解:方法体内的是存在栈的,而方法体外的都是堆里面的。
2014年1月 6日 15:53 | # | 引用
micat 说:
不错,很形象生动,简洁清晰,涨知识了,谢谢
2014年1月 9日 15:48 | # | 引用
sipeny 说:
C++里用free(cls1)清除掉不用的对象实例对吧?
2014年1月14日 16:29 | # | 引用
jpdict 说:
简介易懂
2014年1月25日 15:24 | # | 引用
LppRince 说:
看了大家的评论,有很些人觉得博主的这篇文章写的不够严谨,有些地方不够深入,这点我认同.但这不应该因为这个而抱怨,甚至对博主不敬.毕竟每个人的精力和能力有限.最重要的是博主的文章能够激发和引导我们去进一步探索我们想要的知识.那些抱怨文章不够深入的人,你们是否有认真看过博主给出的连接.我自从第一次无意闯进这个博客到现在,看了博主的不少文章,觉得博主写东西很用心,能做到这个份上已经很可贵了.那些想从博主的文章中得到所有自己想要的东西的人必定会失望.
2014年2月11日 10:47 | # | 引用
Jimmy哥 说:
默默地添加了书签
2014年3月 3日 14:28 | # | 引用
KeenWon 说:
浅显易懂,但是感觉站点的用户引导做的不太好,很多东西“藏”得太深。
2014年3月 9日 15:04 | # | 引用
勇敢的胆小鬼 说:
2014年3月 9日 22:04 | # | 引用
netstu 说:
这明明也是 java 好不好
2014年3月26日 13:29 | # | 引用
mll 说:
what's the meaning of statck in "full stack engineer"?
hoho
2014年3月26日 15:00 | # | 引用
hkant 说:
有的地方不太懂,按照文中所讲
public void Method1()
{
int i=4;
int y=2;
class1 cls1 = new class1();
}
里面的i和y都是放在栈中的,如果class1是类似这样定义的:
public Class class1{
public int k {get;set;}
public void Method2(){
int i2=4;
int y2=2;
class2 cls2 = new class2();
}
}
这个class1对象中的方法Method2里面的局部变量i2和y2是跟随class1放在堆中的还是和i/y一样放在栈中的
2014年7月 2日 15:12 | # | 引用
offerssss 说:
受益匪浅, 感谢分享!
2014年9月11日 10:15 | # | 引用
komac 说:
Full stackengineer is the kind of engineer who knows every kind of technology
2014年10月11日 10:42 | # | 引用
Justme0 说:
最后一幅图中的 i, y, cls1 也是对象,它们放在栈上;cls1 指向的对象放在堆上。
2014年11月 4日 20:33 | # | 引用
chf007 说:
还有第四种用法
全栈工程师 全栈框架(Symfony这种通常叫全栈框架) 的 “栈”是什么意思?
2014年11月17日 23:28 | # | 引用
mrytsr 说:
我也觉得三个是同一个,我点近来以为能解释最近的困惑
比如 协议栈中的栈
OpenStack中的 stack 这些的区别
2015年1月17日 22:54 | # | 引用
junbo Hu 说:
讲的很好,之前面试工作被问到栈,我只答上了数据结构这一层,当被问到堆时,我就懵了,一想数据结构哪里有堆这个东西呀,原来堆是内存空间的概念。
2015年5月29日 15:12 | # | 引用
HOYO 说:
这篇文章讲的偏差有点大
2015年5月31日 02:34 | # | 引用
HOYO 说:
2015年5月31日 02:35 | # | 引用
步行者 说:
似乎有点不打对
2015年6月17日 09:17 | # | 引用
小昏昏 说:
通俗易懂
建议那些评论说有偏差的给予正确的说法,不要说看这,看那,自己总结下塞
2015年7月16日 18:09 | # | 引用
joyc 说:
只要是局部的、占用空间确定的数据,一般都存放在stack里面,否则就放在heap里面。 这句反了吧
2016年6月22日 22:32 | # | 引用
joyc 说:
2016年6月22日 22:37 | # | 引用
11111 说:
对于java 语言解释来说 我是能看懂的。 非常容易理解。
不知道那些 大神 为什么说不对。 哪里不对呢?
我真想看看你们的文章 快点给我链接我要看看。
调用栈 js 里面应该很多。
第三个 我非常的喜欢啊,解释的很透彻 谢谢。
2016年7月14日 16:17 | # | 引用
zoffy 说:
跟csapp上说的不一样
2016年11月23日 12:02 | # | 引用
ken wang 说:
从上图可以看到,i、y和cls1都存放在stack,因为它们占用内存空间都是确定的,而且本身也属于局部变量。
上面这句话描述的不是很准确吧,应该是:i,y 是方法内部的值类型变量,所以内存分配存储在线程栈上,而 cls1 是引用类型所以内存分配在堆上。
2017年6月 9日 14:55 | # | 引用
星辰大海 说:
谢谢楼主,我的疑惑已解决
2017年6月16日 15:29 | # | 引用
剑客不能说 说:
因为它是有结构的,且按次序存放。所有肯定会比不确定的heap快。。。
2017年8月22日 15:13 | # | 引用
aaa 说:
有的人一开口就想否定你。即使心理面认同你,嘴上也会换一种说法对你进行否定,
这在医学上认为是一种疾病,我们称之为SB.
2017年11月 9日 11:28 | # | 引用
Belove 说:
卵老师厉害啊;
感觉自己站在巨人的肩膀上;
迟早有一天会成神.
2017年11月13日 12:10 | # | 引用
Run 说:
+1, 这三个都有着FILO的意思。
协议栈的栈指的是有着上下的结构:“像堆积木一样存放,以实现层层调用”
https://en.wikipedia.org/wiki/Stack
2017年12月 4日 13:12 | # | 引用
isaac_宝华 说:
你好,阮一峰老师,我觉得你文章写得很好,我受益良多,希望转载这篇文章,请问可以吗?
我将转载到:https://github.com/issaxite/issaxite.github.io/issues/118
若不同意,我即立即删除。
2018年1月21日 14:23 | # | 引用
JackLin 说:
@Jex:
同意这位大哥的说法。Stack和Heap使用速度上的更大的差别应该在分配上面。
2018年3月26日 16:06 | # | 引用
JackLin 说:
莫名感觉到楼主内功深厚。
2018年3月26日 16:08 | # | 引用
边鸿飞 说:
其实我是这么想的,读取栈中的一个对象,因为大小是固定的,直接从栈中的一个索引中读取固定长度数据就可以了,而读取堆中的一个对象,就要稍微麻烦一点了,首先需要从栈中把这个对象的引用地址找到,然后再根据这个地址,以及这个对象的类型,去堆中找到这个对象的起始地址,但是对象的大小是不固定的,所以需要用对象的特征,解析出这个对象在内存中起始地址和结束地址,然后把这一段内存中的二进制的一串很长的0和1,反向序列化为对象,这时候这个对象才从内存中取得成功了。等等,好像不对,有问题,为啥呢?这个对象很有可能还引用了别的对象,再找到被引用的对象的内存地址,再按照规则反序列化,但是一个对象不一定就引用了一个对象,要是引用了多个对象呢?被引用的对象可能还引用了别的对象呢,所以一整套过程下来以后,你看看,读取堆中的对象多麻烦啊。索引栈中取对象直接按照长度解析即可,而堆中的对象就麻烦多了。
2018年7月29日 20:45 | # | 引用
taoistwar 说:
技术栈 呢?
2018年11月19日 14:20 | # | 引用
emmm 说:
一个放得乱七八糟的不好找,一个摆放得整整齐齐
2021年7月 4日 13:06 | # | 引用