
谷歌和 Facebook 都只有一个代码仓库,全公司的代码都放在这个库里。
我一直很困惑,为什么要这样做,不同语言的项目放在一个库有什么好处?
最新一期的《ACM通信》(59卷第7期)有一篇论文《为什么 Google 要把几十亿行代码放在一个库?》,作者是谷歌基础设施小组的工程师,可以看作官方对这个问题的详细解答。我读后感到收获很大,下面就是摘录。

一、概况
谷歌最早使用 CVS 进行代码管理,1999年改为 Perforce。那时是一台 Perforce 主机,加上各种缓存机。
当时,全公司的代码就在一个仓库里面,后来一直沿用这种做法。由于规模不断增长,Perforce 已经无法满足需求,谷歌就开始使用自己开发的版本管理系统 Piper。
Piper 架设在谷歌自己的分布式数据库系统(以前叫 Bigtable,现在改名 Spanner)之上,分布在全世界10个数据中心,保证世界各地的谷歌员工都有良好的访问速度。
目前,这个代码仓库包含10亿个文件、3500万次提交记录,大小为86TB,用户达到几万人。工作日每秒有50万次请求,高峰时80万次,大部分来自自动构建和测试系统。
谷歌90%以上的代码,放在 Piper 里面。对于那些开源的、需要外部协作的项目,代码放在 Git,主要是 Android 项目和 Chrome 项目。Git 的特点是,所有历史记录都会复制到用户的本地机器,所以不适合大型项目,必须拆分成更小的库。以 Android 为例,该项目一共包含800多个独立的仓库。
二、Piper 的设计
2.1 结构
整个仓库采用树状结构。每个团队有自己的目录。目录路径就是代码的命名空间。每个目录都有负责人(owner),他负责批准该目录的文件变动。
2.2 权限控制
Piper 支持文件级别的权限控制。99% 的代码对所有用户可见,只有少部分重要的配置文件和机密的关键业务,设有访问限制。
如果机密信息不小心放上了 Piper,文件可以被快速清除。并且,所有的读写都有日志,管理员能够查到谁读过这个文件。
2.3 工作流
Piper 的工作流(workflow)如下图。
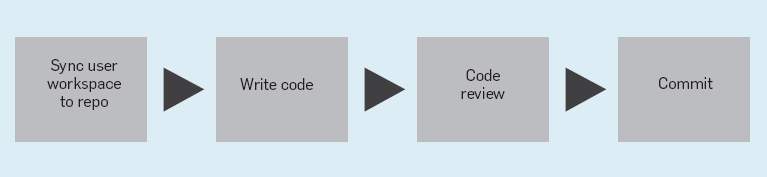
开发者先创建文件的本地拷贝,这叫做"工作区"(workspace)。完成开发后,工作区的快照共享给其他开发者进行代码评审。只有通过了评审,代码才能合并到中央仓库。
2.4 客户端
大多数开发者通过一个叫做 CitC 的客户端,访问 Piper。
开发者通过 CitC 浏览和同步 Piper 上的文件,但是编辑和修改是在自己工作区,里面只保存有变动的文件(一个工作区一般不超过10个文件)。CitC 带有云储存机制,每个工作区就是云上的一个目录。通过代码评审以后,这些文件才从 Citc 合并进 Piper。
不使用 CitC 也是允许的,所有代码保存在本地,最终用 Git 客户端提交到 Piper。不过,由于 CitC 提供更多的功能,目前使用率达到 80% 。
2.5 主干开发
Google 采用"主干开发"(trunk-based development)。代码一般提交到主干的头部。这样保证了所有用户看到的都是同一份代码的最新版本。
"主干开发"避免了合并分支时的麻烦。谷歌一般不采用分支开发,分支只用来发布。大多数时候,发布分支是主干某个时点的快照。以后的除错和功能增强,都是提交到主干,必要时 cherry-pick 到发布分支。与主干长期并行的开发分支,在谷歌极少见。
由于不采用"分支开发",谷歌引入新功能,一般在代码中使用开关控制。这避免了另起一个分支,也使得通过配置切换功能变得容易,一旦新功能发生故障,很容易切换回旧功能。等到新功能稳定,再彻底删除旧代码。谷歌有类似A/B测试的路由算法,评估代码的表现,由于存在配置开关,这种测试很容易实现。
2.6 代码评审
所有代码合并进仓库之前,都必须进行代码评审。大部分评审对所有人开放,任何谷歌员工都可以对代码提意见或者提交变动。
代码评审的依据是《Google 代码风格指南》。谷歌有一个叫做 Critique 的工具,可以查看每一行代码的历史演变。
2.7 自动测试
评审完成后,会自动运行测试。通过测试以后,代码就合并进了 Piper 仓库,整个过程不需要人工干预。
三、优点
单一代码仓库主要有以下优点。
(1)统一的版本
整个公司的代码,有统一的版本和路径,不存在找不到文件的最新版本这样的问题。
(2)广泛的代码共享和复用
任何人都可以浏览和使用全公司的代码,这大大促进了代码的共享和复用。
(3)简化的依赖管理
如果你是库文件或者 API 的作者,因为所有人的代码都在一个库里面,所以很容易找到依赖你的所有下游代码。
每当代码变动,所有依赖你的代码都会自动构建。如果有大量的构建失败,那么系统会自动撤销这次提交。这样也保证了所有代码依赖的都是最新版本,避免依赖不同的版本所导致的冲突。
另外,由于代码的边界很清楚,所以不会发生循环依赖。而且,API的作者也很容易发现,别人怎么使用他的API。
(4)原子性变动
由于每次代码变动所导致的影响,都在一个仓库里面,所以都属于原子性的变动。因此,很容易撤销,或者预先测试它所造成的影响。
为了防止错误提交,谷歌引入了"预提交"(即在提交之前,先分析一下依赖它的代码是否会构建失败)。
(5)大规模代码析构
单一代码仓库为查找和分析代码,提供了巨大的方便。
Google的静态分析引擎 Tricorder 定时运行,对代码进行分析。比如,C++ 11 标准公布以后,很容易找到所有需要改进的变量声明语句,进行性能优化。该引擎还对许多错误提供"一键修正"的功能,同时产出大量的统计数据。
此外,编译器团队也会对不同语言的所有代码进行分析,找出不合理的代码和过时的API。
四、缺点
单一代码仓库的主要缺点是,所有工具都必须自己写,因为市场上没有能够管理这种规模的代码仓库的软件。
五、总结
单一代码仓库,适合提倡透明开放的大型软件公司,不适合小公司和有大量私密代码的公司。
(完)

Loyalsoldier 说:
估计也只有大公司能这么搞……小公司完全没精力和能力
2016年7月 2日 09:10 | # | 引用
kakugyou 说:
“主干开发”和“开关策略”,一直在纠结如何用好git的分支来做版本管理,但目前觉得“主干开发”更适合我的需求。
2016年7月 2日 10:31 | # | 引用
pfchai 说:
对商业公司的代码管理来说,权限控制太重要了,相反git完全没有权限控制,所以更适合开源项目。
2016年7月 2日 13:09 | # | 引用
Zoom.Quiet 说:
看明白了, google 也是从小公司发展起来的,
只是从一开始就定了代码的流程, 并坚持到今天,
只是不得不用越来越NB 的工具来替代了传统的通用版本管理工具而已.
一峰说的 不合适其实已经给出了为什么中国多数公司/团队用不了这种仓库结构....
重点不是团队规模, 而是秘密代码太多...
并不一定是敏感信息, 而是各个组的机密项目,
根本就不能给其它组看到...
2016年7月 2日 22:13 | # | 引用
pdd 说:
这种规模的代码,即使偷了,也很难实现,更不用说个人根本没办法全部拷贝走了。
另外完善的专利法律也是代码保护的后盾。
2016年7月 2日 23:05 | # | 引用
faxiubite 说:
内部工具对项目研发和效率提升极其重要
自己三个公司的体验对比
1.之前在微软外包的时间,在VisualStudio组,微软的内部也有一套瀑布的测试流程,内部自动化工具很完善,
我们当时负责的vs自动化用例,
代码完成后提交,不是立即到代码库,而是会先发起一些自动化扫描,
扫描通过后自动发起CR(必须有人CR后才可以往下走),CR通过后会触发运行,
在核心用例一个都通过和总用例失败不低于一定的指数,才会合并到代码库
这一套机制的背后是内部很完善的自动化工具,
2.在T工作过1年多(时间不多,了解的不清楚),接触过的2个部门,内部工具都是服务于各自部门的,大范围推广的不多,而且定制化的比较多,创新不是很多,
3.目前在A工作,从开始小部门内部工具,到现在各个部门划分比较清晰,工具目前看已经产品化、服务化、集成化,目前还有很多不足,但是总体上已经开始服务于全部公司,效率提升不少,(稳定化、大量的咨询是大痛点)
2016年7月 3日 08:45 | # | 引用
zijin 说:
果然很强大
2016年7月 3日 16:09 | # | 引用
fengyao 说:
当前公司使用的就是“主干开发”模式,使用开关控制新功能的发布。
看了本文,更加深入理解了这个模式的真谛。thanks~
2016年7月 3日 17:56 | # | 引用
夜幕下的猫 说:
我非常想知道“开关控制”是怎么玩的?有没有机会讲解一下,还是说直接能 Google 到?
2016年7月 5日 14:33 | # | 引用
Ying 说:
我理解的应该是引入一个bool的配置变量,当为true开启某个(新的/旧的)功能,false关闭某个功能。
2016年7月 5日 17:49 | # | 引用
Web0571 说:
https://en.wikipedia.org/wiki/Feature_toggle
其实嵌入式年代的宏开关也是类似效果,但总归没有Web领域这么容易解耦。
2016年7月 6日 09:40 | # | 引用
程序猿 说:
如果是快速开发的产品线 迭代非常快 同时间可能并行3个版本在开发 他们的差别支持发布时间上的差异 那么怎么处理呢?
2016年7月 8日 15:32 | # | 引用
Mingfei 说:
不太理解,这一个库的意思,难道工程师要把整个库下载下来?单独项目开发的时候要怎么管理代码?
2016年7月10日 09:48 | # | 引用
windclarion 说:
文中有说明:"开发者通过 CitC 浏览和同步 Piper 上的文件,但是编辑和修改是在自己工作区,里面只保存有变动的文件(一个工作区一般不超过10个文件)。CitC 带有云储存机制,每个工作区就是云上的一个目录。"
是一个库,但不需要全下载到本地,直接在云上工作。这和git不同。
2016年7月11日 13:29 | # | 引用
zskm 说:
阮老师要是能有一个所有文章的目录就好了~~
2016年7月14日 15:56 | # | 引用
StevenZhou 说:
”一个工作区一般不超过10个文件“这个貌似并不准确。
如果你说的工作区是指workspace的话,每个workspace可以创建一个或多个CL(change list,相当于一个pull request), 一个CL很多时候都会超过10个文件,特别是如果像公司级别的dependency发生改变的话,可能要将需要批处理的几百个调用这个dependency的文件放在一个CL里边,修改之后一并提交。
2016年7月18日 11:06 | # | 引用
kissdook 说:
好久不见,阮老师
2016年7月21日 20:38 | # | 引用
vmlinz 说:
看完之后觉得Google的开发流程受到最初使用perforce的影响不小。piper看起来就是一个大规模集群化的perforce 。
除了这个,从Android的AOSP源码管理工具repo还有chrome的代码管理工具也是概念上很类似的。
2016年7月22日 00:45 | # | 引用
刀尖带着鞘 说:
可以公司内部搭建自己的Git服务器,服务器运维控制权限分发
2016年8月 3日 09:45 | # | 引用
钱君 说:
git “主干开发”模式,使用开关控制新功能的发布 这个开关是什么,这个开关要再哪里设置?有人能解答一下吗?谢谢。
2016年8月29日 10:19 | # | 引用
在路上 说:
自己在公司内部搭建GitLab服务器,有很完善的权限控制。
2017年9月26日 10:20 | # | 引用
Shinfield 说:
我们部门也是Git和云端管理代码,但达到Google规模的代码库还是不大可能的,感谢大神翻译并分享心得
2017年11月21日 03:18 | # | 引用
jdxyw 说:
我不太相信这个数据,算下来,一天有400亿次版本控制服务的请求?就算Google再多员工,再多产品线,再多的集成测试和部署,一天400亿?每秒50万?我极度怀疑这个数据啊。
2018年6月 6日 14:20 | # | 引用
金雨 说:
Piper听起来很像ClearCase的用法
2019年2月21日 14:36 | # | 引用
crush 说:
可能一次访问N个文件,算N次
2019年12月 6日 13:54 | # | 引用
linzworld 说:
我们小团队就直接用github或者是github的私有仓库
2020年2月24日 19:45 | # | 引用
hd 说:
哈哈 google 这种集中管理方式效率很高,不是哔哩哔哩那种单一仓库(偷笑),不过对于我们还是 git + 自建仓库就足够了。
2021年6月23日 23:31 | # | 引用
周一见 说:
应该还有很多次是自动化用例之类的,比如一次访问提交会触发10+个测试用例?
2021年7月11日 00:05 | # | 引用
吴镇 说:
人为的不多,主要是自动化(持续测试),每天跑N次自动化,每次都需要从仓库拉代码,然后跑自动化
2021年9月24日 18:13 | # | 引用
zhang 说:
会导致一次提交全公司构建吗
2023年12月11日 11:43 | # | 引用
上沅兮 说:
不会,bazel 可以增量构建,其他构建可以缓存
2025年5月29日 23:17 | # | 引用