
上一次,我用TF-IDF算法自动提取关键词。
今天,我们再来研究另一个相关的问题。有些时候,除了找到关键词,我们还希望找到与原文章相似的其他文章。比如,"Google新闻"在主新闻下方,还提供多条相似的新闻。

为了找出相似的文章,需要用到"余弦相似性"(cosine similiarity)。下面,我举一个例子来说明,什么是"余弦相似性"。
为了简单起见,我们先从句子着手。
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
第一步,分词。
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
第二步,列出所有的词。
我,喜欢,看,电视,电影,不,也。
第三步,计算词频。
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
第四步,写出词频向量。
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到这里,问题就变成了如何计算这两个向量的相似程度。
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, ...])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
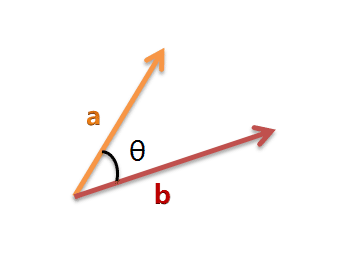
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
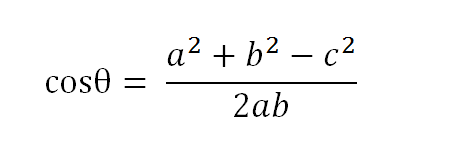
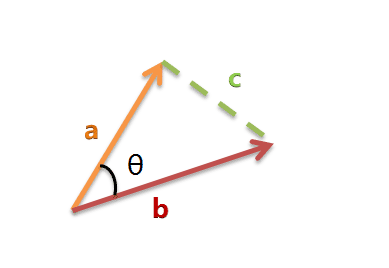
假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
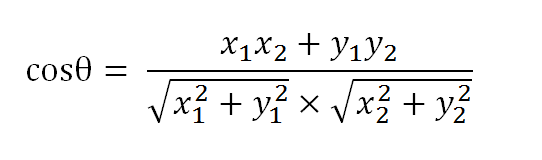
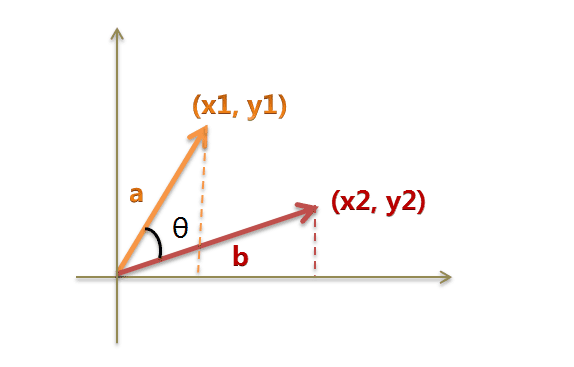
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, ..., An] ,B是 [B1, B2, ..., Bn] ,则A与B的夹角θ的余弦等于:
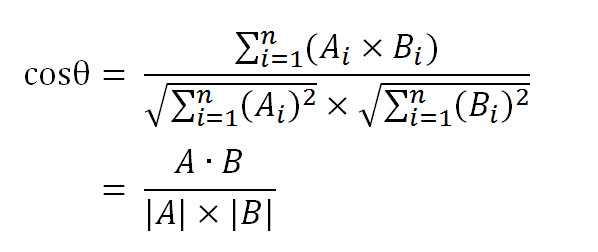
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
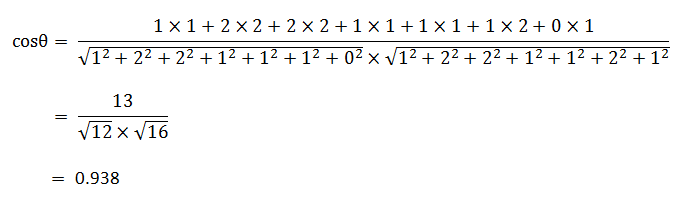
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了"找出相似文章"的一种算法:
(1)使用TF-IDF算法,找出两篇文章的关键词;
(2)每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
(3)生成两篇文章各自的词频向量;
(4)计算两个向量的余弦相似度,值越大就表示越相似。
"余弦相似度"是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用它。
下一次,我想谈谈如何在词频统计的基础上,自动生成一篇文章的摘要。
(完)

Sunday 说:
写的太好了,忍不住抢楼。。。
2013年3月21日 12:20 | # | 引用
going1000 说:
挺好的,简单易懂
2013年3月21日 12:27 | # | 引用
zhenguanxi 说:
之前在吴军的数学之美上看到过,不过还是阮兄的文章比较浅显和详细。
2013年3月21日 12:28 | # | 引用
源 说:
这个系列非常有意思,分词、文章相似性、文章摘要提取,通过这个,可以做一个techmeme.com了。。。。
2013年3月21日 14:41 | # | 引用
Yong 说:
如果上学的时候老师会讲这些东西,我会对数学感兴趣很多...
2013年3月21日 15:03 | # | 引用
弯柚 说:
速度是硬伤啊
感觉您貌似研究了不少相似性算法啊,前面看过了您的PHASH,这次是余弦定理啊,下一次是编辑距离?
2013年3月21日 16:58 | # | 引用
y.chan 说:
浅入深出,好文!
2013年3月21日 19:38 | # | 引用
学生甲 说:
深入浅出体现出功力啊!
2013年3月21日 20:35 | # | 引用
chenzhekl 说:
太棒了!正好最近要做这方面的东西,博主解释的太棒了!
2013年3月21日 21:18 | # | 引用
passenger 说:
請教一下, 如果兩個向量長度不同怎麼處理呢?
2013年3月21日 21:59 | # | 引用
ham 说:
您的文章一直让我能非常清晰的明白 谢谢
2013年3月21日 22:08 | # | 引用
nklike 说:
高深的东西浅显的表达出来,此乃实力
2013年3月21日 22:55 | # | 引用
henzy 说:
刚看数学之美,你这里写的文章更美。深入浅出,博主知识渊博。以后会关注你的文章。加油!
2013年3月21日 23:05 | # | 引用
jqian 说:
不同的补0呗
2013年3月21日 23:51 | # | 引用
Adrian 说:
要是在A句子中,“也”字之前加个“但”,向量偏差不大,可是句子偏差较大。其实根本问题是:为什么得到词频数列表后,问题就成了计算向量?
2013年3月22日 00:54 | # | 引用
zike 说:
简单的补0比较粗糙,在实际操作中通常用余弦定理的前提会是取n个最具代表行的词,例如20词/篇文章,这样以来向量长度就相等了。
2013年3月22日 01:11 | # | 引用
200cc 说:
举例来说:如果要比较线段的长短,那么我们只需要1个维度(长)就可以;如果是比较平面图形,那么我们需要2个维度(长,宽);同理,比较立方体,那么就需要3个维度(长,宽,高)。
每个句子都可以被视为词的组成。因此,要比较句子,就必须先分解每个句子,统计出其中包含的词语(即维度)和词语出现的频率(即维度的值)。然后综合所有的词语,构建一个统一的n维坐标系,才能进行句子的比较。(如果某个句子不包含某个词语,那么它在这个词语维度上的值计为0)。
2013年3月22日 13:34 | # | 引用
book779 说:
阮兄的bolg应该不是用wordpress搭建的,php自己写的?
2013年3月22日 18:20 | # | 引用
jet 说:
阮老师,能讲一讲蒙特卡罗及相关采样算法不?
2013年3月22日 18:50 | # | 引用
zhouzhou2043 说:
说句闲话,网站排名27000了,个人博客,真不不简单啊
2013年3月22日 20:11 | # | 引用
六月 说:
像这种相似性计算的算法应该有很多种吧,可以拿出来介绍介绍
2013年3月24日 21:45 | # | 引用
冰上游鱼 说:
相似度这个概念用的很广,匹配,推荐,聚类都会用到
2013年3月24日 23:46 | # | 引用
问问 说:
2个向量比较计算好理解,N个向量计算COS真的可以表示夹角吗?
2013年3月26日 16:17 | # | 引用
hilojack 说:
将文章相似性转为词频向量的间距 讲得好通俗,谢谢! 如果也能讲讲扭曲粘连验证码的切割与识别就好了
2013年3月31日 22:45 | # | 引用
Dj 说:
既然两句话可以抽象成n维空间中从同一原点出发的两个向量, 为什么不简单计算两个向量指向的端点距离或者距离的平方来给出相似性不是更简单么?
2013年4月 1日 13:07 | # | 引用
书童 说:
你好,请问“假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:”
这个定理是怎么被改写的,根据上面的定理cosB = (a^2 + c^2 -b^2) / (2·a·c)
我没有看到c边,他是怎么被推导为下面那个公式的呢?没想通。请求你帮我解惑一下!
2013年4月 7日 15:39 | # | 引用
ivy 说:
太好了!!简单易懂!!感谢!!
2013年4月14日 10:23 | # | 引用
happylidan 说:
写的太简单易懂了,必须顶一下!!!
2013年7月 2日 11:31 | # | 引用
蒙蒙 说:
这种方法计算的相似度每个词的权重是一样的,有没有办法把权重加入到相似度计算的过程里面?
2013年7月 3日 11:35 | # | 引用
Adam 说:
文章中余弦相似性的英文错了,不应该是cosine similiarity,而应该是cosine similarity。
2013年7月18日 17:49 | # | 引用
noname 说:
写得太通俗易懂了,正需要这方面的知识,看完豁然开朗!
2013年9月 3日 15:42 | # | 引用
jihite 说:
这也是我想说的,向量用tf表示,为什么不用tf-idf表示,不好吗?
idf的计算可以这样:所处理的所有文本数量作为分母
阮老师写的很赞!
2013年10月11日 22:41 | # | 引用
tkzy1 说:
请阮兄多介绍有关文本的知识。
2013年11月17日 16:16 | # | 引用
annabelchina 说:
真是大师,讲得这么明白!
2013年11月22日 17:27 | # | 引用
athrun 说:
看阮兄的微博,涉猎之广,真是令人赞叹
2013年12月12日 11:49 | # | 引用
Josh 说:
请问,如果vector只包含1或0也可以吗?
例如 vector_1 = [0,1,1], vector_2 = [0,0,1]
谢谢
2014年1月24日 16:18 | # | 引用
qq 说:
真的写的很好,刚好有用,感谢!
2014年3月 7日 16:52 | # | 引用
张章 说:
您好,我想在论文中引用您的博客可以吗?
2014年6月 4日 16:44 | # | 引用
小艾 说:
写的真好,即使是我这种刚接触余弦相似度概念的都能一看就明白!赞一个!
2014年8月20日 16:45 | # | 引用
galaxy 说:
你好,在中文中,如何区分两个字如:“喜欢”是一个词,而不是把直接拆分出来进行比较呢?要怎样来判别一个词或者成语呢
2014年8月27日 11:28 | # | 引用
乌龙娃 说:
写的真是太好了,浅显易懂,不得不佩服
2014年9月10日 17:05 | # | 引用
zuiweng 说:
有点明白了,谢谢分享
2014年9月11日 15:36 | # | 引用
eeriee 说:
最后的余弦值要怎么转换为百分比的相似度呢?余弦值=0.938等同于两篇文章相似度是93.8%吗?
2014年10月 4日 18:31 | # | 引用
deyin 说:
讲解得很细致,也很容易理解,图文并茂,很好的文章,赞一个
2014年11月14日 10:07 | # | 引用
kxcf 说:
博主的博文非常给力,解释的太清楚了,赞一个!
2014年11月23日 00:44 | # | 引用
李开太 说:
我最近在研究文本挖掘,看了很多书,一个余弦相似度总是看不明白,看了你的文章,瞬间脑洞大开,大哥,我对你的佩服真是由于涛涛江水,连绵不绝,黄河泛滥,一发不可收。
2014年12月23日 15:59 | # | 引用
woxiangbo 说:
这个算法,貌似没有考虑到词的顺序,
比如
“我喜欢看电影” 和 “电影喜欢看我”
按照词频来统计的话,可能会完全相同,求解答?
[email protected]
2015年1月13日 12:25 | # | 引用
袁鑫攀 说:
写的浅显易懂,不过这类技术在实际中很不实用,因为计算太慢。余弦只是一种距离公式,应用太窄了,还有编辑距离,欧氏距离等等
在实际中,相似度计算,一般是进行1对n的近似搜索,这个n是千亿级别的。
而用余弦作逐一比对是不可能的,所以常用的法则是对每个文档都要形成能用于比对的近似指纹,而这种指纹具有检索性能。
2015年2月 9日 09:54 | # | 引用
hjy 说:
谢谢,讲得好理解
2015年2月11日 00:29 | # | 引用
大力哥 说:
有个问题,用IF-IDF计算时,前提是分词分好的,可分词也是个问题。。。
2015年4月 9日 21:00 | # | 引用
伯劭 说:
你这样没有考虑长度
2015年4月20日 23:12 | # | 引用
死磕馒头 说:
不存在长度不一致问题,即使真的不一致,可进行补全处理,较少的向量补全0
2015年4月30日 10:32 | # | 引用
小菜 说:
刚好要用到。。
通俗易懂
2015年5月 9日 10:18 | # | 引用
小菜 说:
只能说这是余弦相似度
2015年5月 9日 10:20 | # | 引用
sixgod 说:
以前听说过这个概念,没有具体的例子,现在有点形象的理解了
2015年5月13日 16:21 | # | 引用
搞么子 说:
写的不错,对我们编辑来说很有用。。。
2015年6月 2日 21:53 | # | 引用
SulaXD 说:
什麼樣的情況會是180度?
2015年7月 8日 00:44 | # | 引用
wjxdyx 说:
分词的工具有很多啊。百度一大堆的。直接引用就好了。像盘古等等。
2015年7月22日 23:18 | # | 引用
wjxdyx 说:
完全不相干的文章。。如果根据分词来的话。就是把分好的词全部替换成文章里没有的。。就是180
2015年7月22日 23:21 | # | 引用
小白 说:
关于向量的坐标,我能否理解为每次比较时,横坐标相同,例如:
句子A的第1个词是第1个维度,频率是1,用向量表示为[1,1],
句子B的第1个词是第1个维度,频率是1,用向量表示为[1,1],
句子A的第6个词是第6个维度,频率是1,用向量表示为[6,1],
句子B的第6个词是第6个维度,频率是2,用向量表示为[6,2],
句子A的第7个词是第7个维度,频率是0,用向量表示为[7,0],
句子B的第7个词是第7个维度,频率是1,用向量表示为[7,1],
2015年8月 3日 19:14 | # | 引用
吴天 说:
发布文章时,提取他的词频,难道要取出所有文章进行构建他们的词频进行向量计算吗?这应该会严重加重发布时的操作等待时间的,
亦或是异步进行?
2015年9月 7日 11:16 | # | 引用
uu 说:
这里是词袋模型,不考虑词之间的顺序
这个算法,貌似没有考虑到词的顺序,
比如
“我喜欢看电影” 和 “电影喜欢看我”
按照词频来统计的话,可能会完全相同,求解答?
[email protected]
2015年10月28日 11:39 | # | 引用
uu 说:
不会是180度吧,词频向量里的每个元素最小为0,所以算出来夹角最多为90度
比如, [1,0]和[0,1]两个向量
完全不相干的文章。。如果根据分词来的话。就是把分好的词全部替换成文章里没有的。。就是180
2015年10月28日 11:43 | # | 引用
Snake 说:
通俗易懂 精辟精辟
2016年4月 3日 15:06 | # | 引用
梓健 说:
有个问题:如果两篇文章分词后得到的两个关键词集合,这两个集合中元素的数量不一样,但是有交集,请问如何计算出向量呢?
2016年4月 7日 16:39 | # | 引用
madboor 说:
刚看完走进搜索引擎,讲的差不多!
2016年4月 9日 13:58 | # | 引用
感到反感 说:
写的真不错 比看纯算法理解的快多了!
2016年7月 7日 16:11 | # | 引用
gamelife 说:
词频向量长度不一致怎么办?补0吗?原谅我这个渣渣
2016年8月24日 11:36 | # | 引用
小小小小白 说:
必须赞啊!!!言简意赅,简直神了,搜什么都能搜到大神的日志!
2016年11月12日 20:34 | # | 引用
Lesley 说:
真的写的好好!!谢谢大神
2017年1月20日 20:57 | # | 引用
郑逸 说:
非常感谢,很好懂
但不知道能不能分享一下相关的代码
如果可以的表示非常的感谢
能共享的话希望可以发送到我的QQ邮箱
[email protected]
2017年4月15日 11:31 | # | 引用
mingyueyucai 说:
不是 180,是90吧……
2017年4月21日 11:19 | # | 引用
will 说:
牛牛牛! 深入浅出把原理讲的清清楚楚
2017年5月17日 10:26 | # | 引用
鄭宜崴 说:
真的太精闢了!
非常感謝版大!
2017年7月18日 14:20 | # | 引用
小耳 说:
解释的简单易懂,赞
2017年8月12日 08:36 | # | 引用
风信子 说:
jieba分词够用了,可以试试
2018年1月22日 11:37 | # | 引用
海疯 说:
写的真好,每当产品层面遇到算法问题,都忍不住来阮一峰老师博客取经。赞。
2018年的粉丝留
2018年3月 8日 14:58 | # | 引用
学生已 说:
向量长度不同,可以映射到向量空间进行计算
2018年6月 3日 15:28 | # | 引用
charlotte 说:
有代码就好了
2018年7月 9日 10:40 | # | 引用
pencil 说:
你好,请问下,文章里的数学公式是用什么工具做的?
2019年1月31日 17:28 | # | 引用
featue 说:
有道理啊。我就在想如果文章很多,怎样比对出来最近似的几篇,总不能搜索一个词就全部算一下吧。。您说的这个指纹是咋算出来的?
2019年3月17日 16:36 | # | 引用
陈志 说:
感觉这个算法有蛮大问题的,大家只是为了简化就取向量的夹角余弦。挺反对这种程序员装数字家的作风。(不是指楼主,是指最初创立这个算法的GOOGLE程序员之类的)
1.如果截取一半文章,和全文相比,其夹角不为0的概率非常大。
2.词的顺序不同,向量值可能也是一值的
3.求余弦值,和向量的长度没啥关系。哪么,你不是损失了向量长度这个重要信息吗?
4.权值只可能是正值,楼主说的180度显然没有数学常识。
2019年8月21日 14:49 | # | 引用
zsn 说:
在比较两篇文章的相似性时,如何将两篇文章的关键词放到一个词集里呢? 我做出来的是一个关键词一行,怎么变成一个词集呢? 求大神解答~
2021年4月 5日 10:48 | # | 引用
psycho 说:
清晰明了,很感谢!
2021年11月14日 16:43 | # | 引用
zhangsan 说:
不会不一致的,算法是计算了两个句子的所有词。并对所有词做一个统计,没有的词就是0了。
2021年11月25日 16:28 | # | 引用
不会二分 说:
TF-IDF算法是词频*逆文档频率,文中只是用了词频向量,并没有和逆文档频率做乘积,所以不是TF-IDF算法
2023年3月18日 11:31 | # | 引用
李同学 说:
请问阮哥,是否存在这样一种方法,可以从一段话中提取这段话的关键词,从而得知这段话主要是涉及什么领域的,比如说从这段话中提取出的关键词是:长跑,篮球,游泳,象棋,那我可以判断这句话主要是关于“体育”这个范畴的。请问是否存在这样的方法可以判断呢,因为tf-idf只能做到前一步,我找了很多地方都没有找到这样的方法。
2023年4月16日 16:01 | # | 引用
小明 说:
如果两篇文章text1 和 text2 ,text1文章很短但是内容都包含在text2中,根据分词后的余弦相似度计算很高接近100%,就是这周文章长度不一致,而且词出现的很相似,这种要如何计算呢
2024年7月 1日 09:35 | # | 引用
Qsweet 说:
我看了《数学之美》里写的这部分内容,算法和这里写的不一样,先需要建立一个词库,比如六万词的词库,把文章的TF-IDF值都算出来以后,填入6万维的向量。比如一个词是“算法”,在文章里的TF-IDF值是0.012。然后填入6万词的词库向量,算法这个词所在的那个位置就填入这个TF-IDF值。然后比较这个六万维的向量和其他文章生成的六万维向量。因为这样以后算出来的余弦值如果接近1,体现的是相应文章用词比例基本一致。
2024年7月31日 22:29 | # | 引用