
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?

这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。

一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是----"的"、"是"、"在"----这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
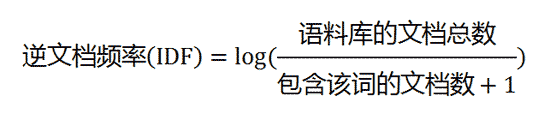
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
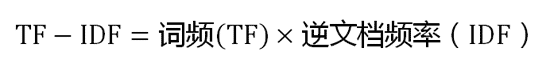
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
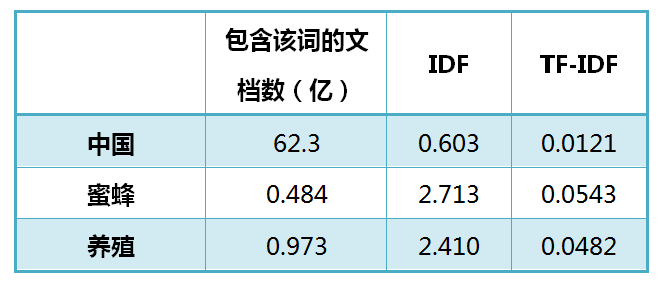
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
下一次,我将用TF-IDF结合余弦相似性,衡量文档之间的相似程度。
(完)

makto 说:
研一的时候选了一门叫 web搜索 的课程,写了一些这方面的代码,很有意思~
2013年3月15日 23:54 | # | 引用
cangzhang 说:
这个好
2013年3月15日 23:58 | # | 引用
Aclaurin 说:
中文并不像英文是以词为单位的,中文的词频统计是怎样实现的呢?
2013年3月16日 00:18 | # | 引用
丕子 说:
先分词
2013年3月16日 00:49 | # | 引用
Chang 说:
分词就是另一门学问了
阮兄的文章真好,尤其是这种数学应用类的
2013年3月16日 02:45 | # | 引用
chenzhekl 说:
对数据挖掘方面的东西很感兴趣,学习了。
2013年3月16日 09:38 | # | 引用
andy 说:
阮兄,能介绍下类似的开源项目 或者 具体的实践篇吗
很感兴趣。
2013年3月16日 12:28 | # | 引用
Isaac 说:
I am just curious if NLTK might provide some of similar functions?
Recently I used the word frequency differences trying to understand ruby cookbook vs python cookbook, my preliminary findings is that python cookbook writers usually use more logical statement than ruby cookbook writers. Ruby is actually more direct, though python might be more 'reasoning' etc. I used NLTK to get the stop words to filter out the word frequency.
2013年3月17日 04:59 | # | 引用
潜行者m 说:
搜索引擎就是靠这种东西收录分析文章的吧?
2013年3月17日 07:02 | # | 引用
reverland 说:
分词
2013年3月17日 12:57 | # | 引用
密斯颜 说:
读阮老师的文章,受益匪浅,,谢谢啦
2013年3月17日 19:31 | # | 引用
fenlin 说:
TFIDF没有体现出单词的位置信息,未能考虑特征项在类间和类内的分布情况
2013年3月18日 00:07 | # | 引用
YangZhixuan 说:
不错~期待后续
2013年3月18日 01:37 | # | 引用
楚材 说:
这个在吴军博士的《数学之美》这本书中都有说明,这个算法就是google发明的。
2013年3月18日 09:19 | # | 引用
inhu 说:
哟西..这个算法值得学习一下..最近买了本数学之美..必须学习下啊!
2013年3月18日 09:32 | # | 引用
10iii 说:
正需要补充这方面的知识。谢谢。
2013年3月18日 09:49 | # | 引用
HeiNotes 说:
好主题。很关心计算机编码怎么把汉语言的`蜜蜂`与`蜜`和`蜂`区别出来,实现有效地提取关键词。
2013年3月18日 10:54 | # | 引用
maas 说:
在《走进搜索引擎》(第2版)中读到过,算法最早的发现者是个数学家,统计过《尤利西斯》的词频,发现了这个规律。
2013年3月18日 12:43 | # | 引用
Yong 说:
这算法牛B了!!!受益匪浅啊,发现在你的博客上总能学到不一样的东西。
2013年3月18日 14:14 | # | 引用
有牙的刺猬 说:
悟性太差,看不到实际流程都不知道怎么下手。
2013年3月19日 15:55 | # | 引用
V客小站 说:
如果已经有了一个词库(字典),那么这个算法应该就可以简单的实现了。假如没有词库,如何自动构造一个词库,比如“的”似乎不能作为一个有意义的词,但“的士”又是一个词。能否自动的识别汉语中的词,加入到词库中。静态的词库存在这样一个问题,因为不断会有新的词汇出现,这个词库很快就会跟不上形势了,而且单纯靠人工识别和处理新的词汇,显然不太可行。
2013年3月19日 16:03 | # | 引用
Ahadoo 说:
您好,阮先生, 我一直想找些英文的IT 博客看, 不知您有什么推荐的?
2013年3月21日 04:04 | # | 引用
Ahadoo 说:
2013年3月21日 04:06 | # | 引用
hxkeyx 说:
介绍下coreseek 分词
2013年3月23日 21:30 | # | 引用
冰上游鱼 说:
恩 喜欢简单有效的算法
2013年3月24日 23:44 | # | 引用
M16 说:
阮兄可否知道Summly应用其算法实现?与TF-IDF类似?
2013年3月28日 09:34 | # | 引用
hhrmatata 说:
本文使用google搜索返回的网页数量计算IDF,但是google api免费限额是一天搜索100次,明显不能满足分析一篇文章的要求,不知有不有更好的语料数据计算IDF?
2013年4月 4日 09:52 | # | 引用
three_zone 说:
2013年4月15日 00:50 | # | 引用
车君失羊 说:
IDF的计算是如果所有文档中都没有该词,那这个词是怎么出现的呢?
2013年6月 1日 21:37 | # | 引用
saieuler 说:
如果蜜蜂不是词,那么它蜜和蜂出现的概率的乘积应该是蜜蜂一起出现的概率。否则如果蜜蜂一起出现的概率远大于蜜和蜂分别出现的概率,说明蜜蜂是个词。
2013年6月14日 10:41 | # | 引用
staticor 说:
结合数学之美 matrix67的内容 会大有裨益.
2013年7月19日 10:39 | # | 引用
无命 说:
哥啊,你是神啊,简单明了的点出了算法的原理及应用
崇拜啊
2013年8月 1日 17:13 | # | 引用
raymond_lei 说:
受教了。同样对这个问题很迷惑,看来google真是个宝库。
2013年8月27日 18:19 | # | 引用
jihite 说:
缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
这句话有点不妥,毕竟tf-idf,词频还要*idf呢,而不是单纯从tf衡量
2013年10月11日 22:19 | # | 引用
taotao945 说:
写得很好,学习了!有个疑问,如果是很短的文本,例如微博,使用TF-IDF貌似就不适用了啊。比方说关于嫦娥三号登月的热门微博,有成千上万的人讨论这个话题,那么“嫦娥三号 登月”在每一篇出现的次数很少,即TF很小,与普通的词差别不大;而包含这个话题的帖子却很多,因为大家都在讨论这个话题,那么IDF就会很小,这样一来,没办法将本来重要的词提取出来了。请问博主有什么看法吗?
2013年12月16日 09:27 | # | 引用
alphali 说:
计算IDF的语料库你好像想错了吧?不应该在话题的众多帖子中计算吧?愚见
2014年2月14日 14:03 | # | 引用
coder 说:
非常受用!多谢! 请问一下博主,如果想要提取一句话中的关键词,如:“不如我们明天去郊游吧,你说呢?” 提取获得“我们 明天 郊游” 这个要如何实现呢?
2014年3月 3日 10:57 | # | 引用
huals 说:
这个是自然语言处理领域的语义角色标注,你可以搜相关论文看看
2014年3月26日 16:19 | # | 引用
刘华强 说:
很厉害,很是佩服。。表达能力很强,果断收藏
2014年4月29日 17:38 | # | 引用
死月 说:
是不是在应用 TF-IDF 之前,需要有一个比较完备的词频库和逆词频库呢?
2014年8月11日 19:26 | # | 引用
zuiweng 说:
浅显易懂,谢谢分享
2014年9月11日 15:22 | # | 引用
MarzinZ 说:
仔细想想,这不就是naive bayes嘛!
2014年9月18日 09:06 | # | 引用
enao 说:
使用分词工具就可以了。
2014年11月 6日 21:54 | # | 引用
kxcf 说:
最近刚学自然语言处理。这种词可能是一些新出现的词语(比如人名),在语料库中没有现成的。而另一方面,分词算法如果足够好是能够识别出这些没有在语料库中出现的新词汇的,所以计算IDF时会遇到语料库中没有的词汇。
2014年11月23日 00:40 | # | 引用
Lumia 说:
这个需要一个庞大的语言库,如果我不告诉电脑蜜蜂是重点词汇,电脑又怎么知道呢。
2014年11月24日 13:48 | # | 引用
yueyanglou 说:
简单而使用的算法,您讲解的也很好。
我有一个问题:难道每篇文章都要建立一下词频和权重么?
如果建立词库的话,如何建立?
2015年3月17日 10:40 | # | 引用
王坚 说:
逆文档率是否应该是分子+1?才能保证逆文档率不为0
2015年4月25日 17:48 | # | 引用
姚锟 说:
我发现数据量比较小的时候,tfidf基本都是0
2016年3月 4日 12:17 | # | 引用
盧彤 说:
好棒的闡述阿~對於文科的圖書館學學生來說真是一大幫助 謝謝!!
2016年3月16日 15:47 | # | 引用
weaver 说:
你好,请问一下,我在BM25公示上看到的IDF公式是
log( (N-n(qi)+0.5)/n(qi+0.5) ),为什么会同你文章中的不一样呢?
2016年5月12日 15:25 | # | 引用
matianyi0307 说:
0.5是BM2.5里的平滑因子,相当于让IDF值更平滑一些
2016年5月17日 19:52 | # | 引用
does.zhu 说:
TF-IDF算法有多种变种形式,理解意思,择其一即可。
2016年5月23日 09:46 | # | 引用
化蝶飞 说:
学到了,很实用的算法讲解,有助于理解搜索引擎的工作原理
2016年7月30日 00:12 | # | 引用
ash_xie 说:
这个问题我也想同问
2016年9月27日 22:57 | # | 引用
王茜 说:
楼主,能否把您写的提取关键字和文章相似度比的代码实现发到我邮箱啊?我最近写论文正好用到此算法,您能发给我代码看看嘛?非常感谢您!
2016年11月 2日 11:17 | # | 引用
jk.yu 说:
很棒的解释。看到用google搜索‘的’得到整个中文库的数量时简直不能更膜拜!
ps:对中文来说,做TF-IDF提取关键词之前需要加一步分词处理吧?
2016年11月29日 12:38 | # | 引用
cloud 说:
非常感谢您的讲解!对我们的学习很有帮助!谢谢您!
2017年5月15日 12:35 | # | 引用
那日苏 说:
文中:“可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。”该句中,语言替换为语料库,更合适吧。
2018年5月 1日 22:24 | # | 引用
Duke 说:
看看jieba分词
2018年6月 7日 10:42 | # | 引用
zzh 说:
IDF取log时底数为什么是10?可不可以用“语料库的文章总数”?
2018年8月31日 11:48 | # | 引用
zcy 说:
我想抖个机灵,如果一篇文章题为《“的”字的分析与应用》,这个算法还能用吗
2019年5月16日 10:19 | # | 引用
伊文 说:
相当棒的例子
2020年4月24日 10:39 | # | 引用
吴相鑫 说:
你好,阮老师。对于IDF公式中的log,按照你下面蜜蜂例子的表格应该是以10为底的lg,而上面是log。不知道是哪里错了,还希望老师指正。
2020年11月28日 14:38 | # | 引用
李逍遥 说:
可以先对中文进行分词,把句子转化成词语。了解一下jieba
2022年11月23日 11:02 | # | 引用