
二年前,我写了《相似图片搜索的原理》,介绍了一种最简单的实现方法。
昨天,我在isnowfy的网站看到,还有其他两种方法也很简单,这里做一些笔记。
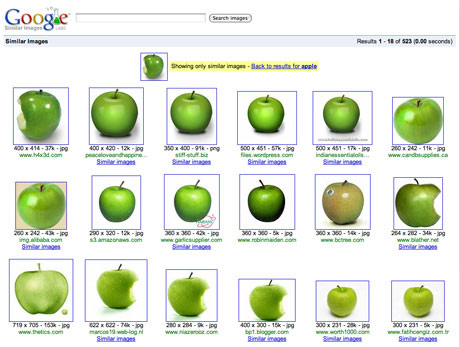
一、颜色分布法
每张图片都可以生成颜色分布的直方图(color histogram)。如果两张图片的直方图很接近,就可以认为它们很相似。
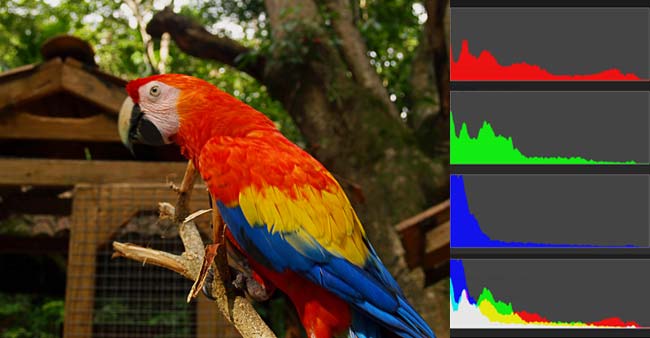
任何一种颜色都是由红绿蓝三原色(RGB)构成的,所以上图共有4张直方图(三原色直方图 + 最后合成的直方图)。
如果每种原色都可以取256个值,那么整个颜色空间共有1600万种颜色(256的三次方)。针对这1600万种颜色比较直方图,计算量实在太大了,因此需要采用简化方法。可以将0~255分成四个区:0~63为第0区,64~127为第1区,128~191为第2区,192~255为第3区。这意味着红绿蓝分别有4个区,总共可以构成64种组合(4的3次方)。
任何一种颜色必然属于这64种组合中的一种,这样就可以统计每一种组合包含的像素数量。
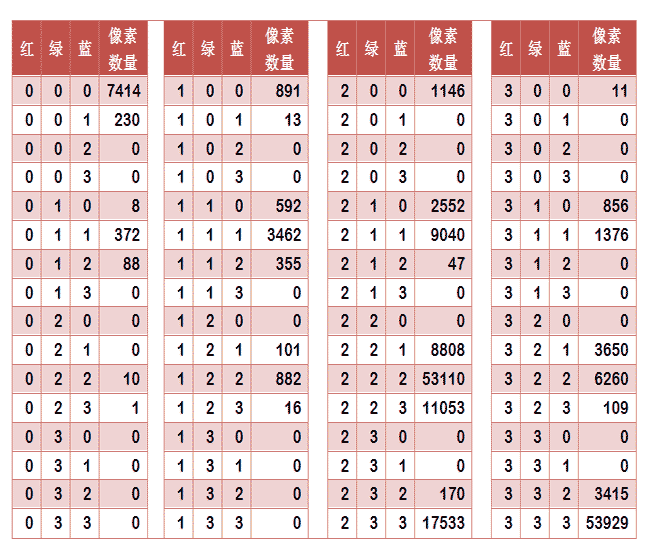
上图是某张图片的颜色分布表,将表中最后一栏提取出来,组成一个64维向量(7414, 230, 0, 0, 8, ..., 109, 0, 0, 3415, 53929)。这个向量就是这张图片的特征值或者叫"指纹"。
于是,寻找相似图片就变成了找出与其最相似的向量。这可以用皮尔逊相关系数或者余弦相似度算出。
二、内容特征法
除了颜色构成,还可以从比较图片内容的相似性入手。
首先,将原图转成一张较小的灰度图片,假定为50x50像素。然后,确定一个阈值,将灰度图片转成黑白图片。



如果两张图片很相似,它们的黑白轮廓应该是相近的。于是,问题就变成了,第一步如何确定一个合理的阈值,正确呈现照片中的轮廓?
显然,前景色与背景色反差越大,轮廓就越明显。这意味着,如果我们找到一个值,可以使得前景色和背景色各自的"类内差异最小"(minimizing the intra-class variance),或者"类间差异最大"(maximizing the inter-class variance),那么这个值就是理想的阈值。
1979年,日本学者大津展之证明了,"类内差异最小"与"类间差异最大"是同一件事,即对应同一个阈值。他提出一种简单的算法,可以求出这个阈值,这被称为"大津法"(Otsu's method)。下面就是他的计算方法。
假定一张图片共有n个像素,其中灰度值小于阈值的像素为 n1 个,大于等于阈值的像素为 n2 个( n1 + n2 = n )。w1 和 w2 表示这两种像素各自的比重。
w1 = n1 / n
w2 = n2 / n
再假定,所有灰度值小于阈值的像素的平均值和方差分别为 μ1 和 σ1,所有灰度值大于等于阈值的像素的平均值和方差分别为 μ2 和 σ2。于是,可以得到
类内差异 = w1(σ1的平方) + w2(σ2的平方)
类间差异 = w1w2(μ1-μ2)^2
可以证明,这两个式子是等价的:得到"类内差异"的最小值,等同于得到"类间差异"的最大值。不过,从计算难度看,后者的计算要容易一些。
下一步用"穷举法",将阈值从灰度的最低值到最高值,依次取一遍,分别代入上面的算式。使得"类内差异最小"或"类间差异最大"的那个值,就是最终的阈值。具体的实例和Java算法,请看这里。

有了50x50像素的黑白缩略图,就等于有了一个50x50的0-1矩阵。矩阵的每个值对应原图的一个像素,0表示黑色,1表示白色。这个矩阵就是一张图片的特征矩阵。
两个特征矩阵的不同之处越少,就代表两张图片越相似。这可以用"异或运算"实现(即两个值之中只有一个为1,则运算结果为1,否则运算结果为0)。对不同图片的特征矩阵进行"异或运算",结果中的1越少,就是越相似的图片。
(完)

gofane 说:
看了前几篇关于摘要的算法很受用,相似图片搜索也是很有趣的应用,学习了~~
2013年3月31日 20:54 | # | 引用
cangzhang 说:
好文!
2013年3月31日 21:21 | # | 引用
cangzhang 说:
第一种方法想到过,第二种学习了!
2013年3月31日 21:30 | # | 引用
Charlie Chiu 说:
贵文的“阈值”写成了“阙值”,不应该啊。
2013年3月31日 21:52 | # | 引用
阮一峰 说:
@Charlie Chiu:
谢谢指出,已经改正了。
我从来没注意过这个问题,一直写“阙值”,都习惯了。
2013年3月31日 22:14 | # | 引用
reverland 说:
第一个反应是用来识别验证码……
2013年4月 1日 09:36 | # | 引用
hightman 说:
好文!这几种方法本质上都是计算图片的 perceptual hash,再通过 hamming distance 表示差异。最近正好也在了解这方面的相关知识,目前碰到的难点在于面对海量(其实只是比较多)图片筛选时,如何把匹配速度优化到一个可接受的范围呢。
2013年4月 1日 09:56 | # | 引用
Junyi 说:
Adobe在这方面的技术积累那么深,如果做了图片搜索,是不是可以秒杀其他公司呢?
2013年4月 1日 16:04 | # | 引用
flowaters 说:
匹配速度可以用索引来做,主要还是hash的质量怎么提高。
2013年4月 1日 16:51 | # | 引用
hightman 说:
像这样的 KNN 问题,有哪些成熟易用的算法或库推荐吗。此外遐想何时能有一个像 strstr() 一样的 imgimg() 功能啊
2013年4月 1日 20:37 | # | 引用
xlzhu 说:
识别图片中的线段是否中断,博主是否有思路呢?之前考虑过对比,但貌似没找到好的算法
2013年4月 2日 00:01 | # | 引用
cupid 说:
我以前也研究过这样的算法。
会不会有多张图片,直方图很类似,但图片完全相同呢?
毕竟没有通过图片中的轮廓边缘来匹配。
2013年4月 2日 09:17 | # | 引用
God 说:
这技术非常有潜力,不仅仅局限于图片搜索,可以用到图片伪原创,验证码识别等等各类内容感谢阮大侠
2013年4月 2日 09:33 | # | 引用
Patrick 说:
2013年4月 2日 13:19 | # | 引用
Kira 说:
Adobe已经做了,单机版的Photoshop Element就有相似搜索
2013年4月 3日 09:11 | # | 引用
XX 说:
这些都是目前人能想到的,利用视觉或数学方面的来寻找相似性的图片。人类及动物是如何识别相似图象的呢?这个更有趣。
2013年4月 6日 14:58 | # | 引用
冰上游鱼 说:
图像处理很有意思啊。感觉最重要的就是如何定义特征,如何提取特征了。
2013年4月 8日 11:07 | # | 引用
第04号 说:
很有道理,感谢示例代码的分享。
文章很好,详略有度。
2013年4月 8日 12:44 | # | 引用
熊猫家族 说:
讲解的很详细,收藏啦
2013年4月11日 14:16 | # | 引用
linyuansen 说:
阮哥的东西都写得简单易懂,写得太好了
2013年4月15日 10:44 | # | 引用
RedoxB 说:
你的第一篇文章以及此篇文章的思路我大概也想到过,第二种方法有点新颖。
本来以为可以凭着兴趣玩出个图片搜索引擎,原来谷歌早就有了!唉。少年还需努力!
2013年4月19日 22:45 | # | 引用
xiasl 说:
有个疑问,如果是将图片生成hash特征值,再采用布隆过滤器来比对效率会高的惊人,Google就用这个方案解决垃圾邮件问题。不过如此一来那就和相似比对背道而驰了。因为 这是精确比对而非相似比对,差一个字节都无法比对上。不知道兄台你有啥好想法没有^_^
2013年4月29日 20:55 | # | 引用
祁磊 说:
求参考资料链接,楼主可以列一下主要的参阅材料,网站什么的,信息越多对大家越好哈。
求了解更多啊。
2013年5月 3日 09:27 | # | 引用
potatos666 说:
经常阅读您的博客,收益匪浅。谢谢您提供的宝贵知识!
2013年5月 6日 11:58 | # | 引用
josico 说:
请问什么叫 前景色和背景色的"类内差异最小"和"类间差异最大" 呢?
为什么找到这么一个让"类内差异最小"或"类间差异最大"的值 就是阀值,轮廓就越明显呢?
望高手赐教
2013年5月16日 19:21 | # | 引用
josico 说:
额。。。上面的那个问题已经知道了 问题挺小白了
研究了一个晚上 感觉这种算法貌似有点问题
你是这么写的‘首先,将原图转成一张较小的灰度图片,假定为50x50像素’
这里的 50*50 感觉有问题
有一些桌面壁纸 是那种左边都是背景,真正的前景在图片的最右边,这样取他的50*50岂不是把主干弄没了?
但要是不进行缩放 确实很影响效率 那到底该如何是好呢?缩小的比例,多大为好呢?
2013年5月17日 00:05 | # | 引用
wangwenchen 说:
我已经根据您的思想做出了一个图片搜索引擎。请问可不可以提供以下您所参考的文献或者网站信息等资料吗?非常感谢!:)
2013年5月21日 03:26 | # | 引用
于梓峤 说:
可不可以把图片转为4位色然后查询?查询结果按匹配度排列
2013年5月26日 10:53 | # | 引用
edisonqkj 说:
感谢博主提供了这么好一篇博文,我学习了!我特意测试了一下第二种算法,发现
“类内差异 = w1(σ1的平方) + w2(σ2的平方)”这里是不是描述错了,括号里的值应该等于方差,而不是方差的平方。因为我用“类外差异”也计算了一下:括号里若是方差的话,两个差异方法的极值是相等的;若是方差的平方的话,极值就不等于了。
2013年6月17日 17:38 | # | 引用
王敏 说:
原文:如果每种原色都可以取256个值,那么整个颜色空间共有1600万种颜色(256的三次方)。
RGB每种原色取256个值,即深度为8,2^8=256,整个颜色空间2^(8+8+8)=2^24约1600万,24次方,您笔误了吧
2013年7月 9日 11:32 | # | 引用
王敏 说:
两种方法单独使用都有各自的局限,结合起来不错,学习了。
颜色分布的局限:假如100*100的两张图,一张分割成50*50的4个小块,并各渲染成4种比如红、黄、蓝、绿;另一张分割成25*25的16个小块,各小块交替渲染成上面的4种颜色。视觉上完全不同的两张图片,因为两张图上各种颜色的总像素数一样,会被认为是相似的。
内容特征法的局限:可以避免上面的问题,但忽略了色彩差异,比如车道指示灯,分别发的红光、绿光箭头信号,如果灯体本身是黑色,不管是发红光还是绿光,都会被分离成前景色。
2013年7月 9日 12:04 | # | 引用
awnuxkjy 说:
简单明了,不错的好文
2013年8月11日 15:17 | # | 引用
cheng 说:
我发现第一种计算方法有一个问题。
如果图片是局部色彩相近的图片,用黑色遮掉大部分保存为新图,然后与原图比较
发现余弦计算值>0.9(取决图片色彩是否平均,即每个部分都差不多)
这是因为会出现两个向量平行的情况,黑色的rgb值为 0
2013年10月16日 16:39 | # | 引用
luochen1990 说:
太好了, 正需要用到这个, 学习了, 谢谢阮大神的分享!
另外顺便帮忙debug一下下:
1. 所有灰度值小于阈值的像素的平均值和方差分别为 μ1 和 σ1
2. 类内差异 = w1(σ1的平方) + w2(σ2的平方)
根据句2推测句1中的σ1和σ2是否应该是"标准差"而不是"方差"?
2013年10月22日 10:31 | # | 引用
Liu Jinxue 说:
感觉这几个方法都只能根据缩略图查找源图像,或者说非常接近的图像,
要想真正基于图像内容去检索图像还是不够
2013年10月29日 15:14 | # | 引用
元子 说:
前面两种方法不错~第三种好像和Percept Hash类似吧,只是这里扩大来指纹范围
2013年11月13日 21:15 | # | 引用
Fangzhou 说:
第二种方法 哪些是前景哪些是背景是怎么知道的呢 不知道我理解错或者漏了什么没有
2014年7月 5日 17:24 | # | 引用
iwbpm 说:
很有趣,很想了解证件照中人脸识别的原理跟这种技术有何不同
2014年12月16日 21:10 | # | 引用
孔雀东南舞 说:
看完了,通俗易懂。之前我看过别人做交通灯的识别的例子,也用到了图像处理的技术,其中有一个关键就是转为二值图时阈值的选取。
对于交通灯识别中自动选择合适的阈值,我以前想到一种非常粗糙的方法:先得到黑白图,然后得到黑白图的均值(例如90),最后根据这个均值选取阈值例如定为均值的一半,即45。(当然这种算法是很粗糙的)
通过Photoshop软件模仿可知,事实上对于同一幅图,采用任何阈值的效果都不会太好,更好的方法是对一幅图采用2-3次不同的阈值,然后将这2-3张图通过某种方式合成到一起,这样得到的阈值图是最完美的,可惜这种处理让人操作Photoshop软件是可以完成的,但通过一套完全自动化的算法程序去实现却困难重重。
2015年1月 3日 17:22 | # | 引用
小蜗牛 说:
2015年3月27日 15:42 | # | 引用
jmychou 说:
第3张图片中,共有64中组合,红绿蓝分别有4个区,但是这些组合中(每一行中)的这个像素数量是怎么算的呢???小白一枚,求教大家。。。谢谢!
2015年4月14日 20:22 | # | 引用
michaelWong 说:
最后一种“内容特征法”,其实也只能搜索缩略图,而不能搜索一幅图像为另一幅图像一部分的情况,这种情况,反倒相似性最差,对吧
2015年5月12日 09:37 | # | 引用
王念一 说:
关于最后一步的xor有不同看法。
如果这样的话,我仅仅将单位为1*1的黑白网格移动1px就会使xor出来的结果全部为1.
2015年12月27日 12:40 | # | 引用
丁健恢 说:
您好,我现在在学习图像搜索,但是最近遇到了一些问题,不知您是否方便能够给我一些指导。
2016年4月20日 18:35 | # | 引用
大壮 说:
这种算法的局限性适用性应该很小吧? 同一张图片 旋转不同的角度 ,按照这种算法,相似度咋样 ?
2016年5月 6日 16:47 | # | 引用
大壮 说:
能否讲一些 人脸检测、人脸训练、人脸识别 方面的知识 ?
2016年5月 6日 16:49 | # | 引用
T.A 说:
的确是这样子的。。
2016年7月21日 16:45 | # | 引用
brml 说:
颜色分布中像素的数量和直方图有什么关系?
2016年9月13日 15:46 | # | 引用
李健 说:
话说...直方图的那种方法里使用汉明距离效果好不好啊
2016年10月16日 14:38 | # | 引用
四四 说:
感慨万千
2017年12月13日 20:06 | # | 引用
livmortis 说:
时过境迁,现在是cnn天下
2020年1月18日 19:06 | # | 引用
小猫 说:
收益匪浅,感谢!!
2020年4月22日 15:51 | # | 引用
炉子 说:
经典永不过时啊,CNN中的卷积操作其实也是滤波器啊
2022年4月13日 17:43 | # | 引用